AI大模型的仰望星空和脚踏实地
AI正在以天为周期进化,给人前所未有的压迫感,AI读心术?数字生命?AI大模型正在以其无与伦比的效率颠覆我们的生活。比尔盖茨表示:这就像当年我第一次见到图形界面操作系统。黄仁勋在发布会上强调,我们正在经历又一个Iphone Moment
ChatGPT在今年1月推出,也就是推出仅两个月后。活跃活跃用户就达到了1个亿,成为了历史上增长最快的消费应用,排名第二TikTok用了13个月才达到1个亿
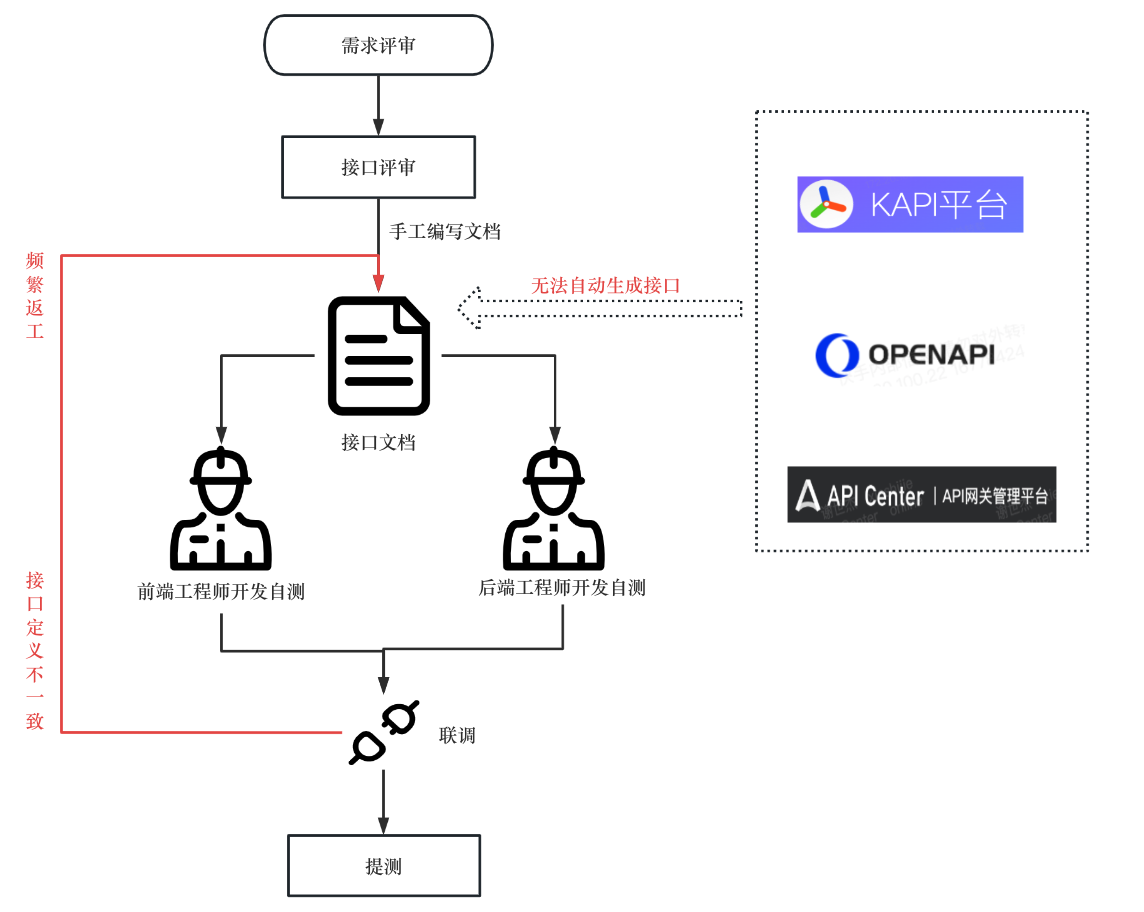
这两个月世界变化巨大,而变化来自于AI。
3.15号,Open AI发布了GPT 4,也就是新版本的AI大模型,这就像第一次图形界面或iPhone第一次发布,带给了互联网无与伦比的冲击。
OpenAI掀起的狂潮
3.16号 微软发布Copilot
微软发布的office办公工具基于GPT大语言模型的,以后不管是在world Excel PPT还是邮件系统,都会多出来一个对话框,也就是一个人工智能助手,他可以帮你改文章做PPT查询数据。
- 比如当你在用Excel查公司数据的时候,你可以跟他直接说,请把过去一年公司增长的原因找出来,他就会把关键增长部门的数据划重点,提示你。
- 如果你错过了一个重要的会议,可以根据会议记录问他,会议主要讨论了啥呀,各方面都有什么观点啊,最后有什么问题没有被解决啊
- 当然也可以用word文档直接生成PPT
相当于让每个人,都拥有了一个高校毕业的秘书

3.16号 Midjourney V5发布
midjourney是AI图片生成工具,基本上解决了之前AI画不好手指的问题,整体产出的图片不像之前的版本那么天马行空,但却更接近真实场景,很多时候让人难辨真假
https://www.midjourney.com/showcase/recent/


3.16号 百度发布文心一言
百度的大语言模型文心一言3.16号发布公测,成为第一个发布大模型语言模型的国内互联网大厂
3.21号 英伟达年度开发者大会
在大会上,黄仁勋做了演讲,通篇没有一处提到游戏显卡,而是在软件部分,发布了100多个基于英伟达特用GPU和扩大架构的加速计算工具
包括流体力学仿真数据库处理、光刻机眼膜设计和AI等,更新了工业园宇宙Omniverse,在硬件部分发布了4款AI推理芯片,整体上把AI的运算效率提升了一个档次,还发布了三个基于AI大模型的云服务,分别面向文本处理、图片处理和生物医药的研究
核心思想就是:All In AI

3.21号 Google Bard聊天机器人公测
GPT-4发布一周后,谷歌聊天机器人Bard开放测试
高情商:跟搜索保持距离,搜索的补充体验
低情商:依托答辩
3.23号 Github发布copilot x
随着 OpenAI 的 GPT-4 模型的发布,GitHub 紧接着就发布了新版本的 GitHub Copilot X。Copilot X 的 AI 模型采用的是最新 OpenAI GPT-4,毕竟 GitHub 是微软的亲儿子。
GitHub Copilot X 致力于改进开发者体验,将提供聊天和语音界面,支持拉取请求,回答文档问题,并通过 GPT-4 实现更个性化的开发者体验。使用 GitHub Copilot X,它可以解释代码的用途,还可以在遇到 bugs 时让 Copilot X 尝试去修复它,甚至还可以顺带生成单元测试。
3.23号 Runway发布Gen 2
不同于上个版本Gen 1,需要输入文字加图像才能生成视频,Gen 2只要输入文本就能生成视频
https://research.runwayml.com/gen2
3.25号 Open AI推出ChatGPT插件能力
该能力可以把你的网站或者app跟Chatgbt连上。
起到作用类似于比如说你你把美团跟chatgbt连上,然后用户就可以给AI助理下指示,周末我要带女朋友去大理玩,然后他就会根据美团上的商家数据和用户评论数据,过几秒钟就帮你把行程酒店机票餐厅全都安排了,然后你跟他说太贵了,然后他就会给你整体根据优惠然后再安排一遍
这就开始想象chatgpt应用的无限场景,更大的改变是有可能以后大家就不上美团了,也不再应用商城下美团APP了,而是直接在chatgpt里面用美团或者别的什么生活服务APP了,直接重购了互联网流量入口。
AI正在以天为周期进化,给人前所未有的压迫感,对此比尔盖茨和英伟达老板黄仁勋的表态是最有代表性的
比尔盖茨表示:这就像当年我第一次见到图形界面操作系统
黄仁勋在发布会上三次强调:我们正在经历又一个iPhone Moment
比尔盖茨靠着抄MAC图形界面操作系统操的够快以及设计出了快速扩张的商业模式,率领微软登上巅峰成为世界首富。黄仁勋因为错过了iPhone带来的移动互联网革命,他的公司股价从2007年高峰的接近10美元一度掉到接近1美元。所以我相信这两个人对他们口中的那个时刻一定是印象深刻的
而此次此刻恰如彼时彼刻!
仰望星空
AI大模型的底层逻辑
这是一张末代皇后婉容的照片,AI模型上色之后就成了这样

同时他还可以有很多别的配色

那么AI是怎么完成黑白照片的上色的呢?
如果让我这个人类去给这张照片上色的话,我能想到两种方法
方法1:我先去调查婉容这件衣服的材质,甚至尝试去找到这件衣服的本体,在结合史料上拍张照片的时间地点、当天的天气光照,确定一种最有可能的颜色给它涂上去,这种方法叫做分析推理方法。
方法2:我随便找个看着不那么突兀的颜色,就给他涂上去,所有的背景事物照此操作,最后出来的照片像那么回事就行,因为我看过很多女人穿着类似衣服的彩色照片,这种方法我们姑且称之为套模板
AI并不擅长分析推理,但他非常擅长套模板
然后总结成模板到处套,特别是在最近这一轮大模型革命之后,AI变得非常非常擅长总结模板到处套,这既体现为他无与伦比的效率,也体现为他无人可及的能力。

无与伦比的效率
AI大模型很难承担真正的原创性工作,也就是说他无法替代去形成目标决心底层的策略,但他能比任何人都更高效的完成扩展翻译总结查找
这里的扩展翻译总结查找,都是广义上的说法

于是基于广义扩展翻译总结查找,围绕AI大模型就产生了大量的应用
- 比如说文字转图片的midjourney、stable diffusion、dall·e 2
- 文字转PPT的Tommy、copilot
- 文字转视频的Runway
- 文字转网站代码的copilot x
- 等等等等
现在美国的互联网新产品发布平台Product Hunt,上面已经有一半以上的新发应用是基于AI,帮你解决各种各样的小问题的:比如说在繁杂的Excel数据当中找出关键的增长指标就是查找,这些本来需要投入几小时甚至几天去完成的工作,现在AI能在几秒钟之内帮你完成
在用AI完成基础的工作之后,数据会保存在数据库里,而不是人类的脑子里,也就是提取和传输的限制条件是内存和限宽,而不是人类的发声习惯,信息在组织内部上传下达平级沟通的效率也急剧加速
就比如在管理软件领域的大数据分析,现在的大型连锁商店,都会收集大量经营数据来分析,但是当运营人员真的提出要看某些数据的时候,首先数据涉及到敏感的商业机密不能让你随便看,然后你的电脑也跑不了那么大的数据库,这时候就需要专业的工程师去帮你调取特定的数据,会根据先来后到轻重缓急,给调取数据的需求排个序,你会进入到排队队列,真正拿到数据的时候可能是2个月以后了,而AI大模型能把这个时间缩短到几秒钟。

实际上我们日常的工作当中,只有非常非常少的一部分是严格意义上的原创,而有大量的信息搜索总结翻译扩展,大量的沟通上传下达,当AI充分介入之后,这些流程将会不复存在,大集团公司老板和国家领导人将可以直接获取最基层的信息,而绝大多数产品的开发周期都会缩短到一天之内,上午形成想法晚上网站上线,甚至配合日益成熟的3D打印技术,上午形成想法晚上零件入库,这就是AI大模型能给我们带来无与伦比的效率。

AI读心术
更激动人心的是AI创造了新的可能性
有一种医疗诊断技术叫做FMRI(功能性磁共振成像)可以观测记录到大脑血流的微小变化,大脑在工作的时候,比如说看一张图片,必然会导致各部分的神经元产生不同的对能量氧气的需求,进而导致血流量的微小变化,而这个数据是可以通过FMRI记录下来的

那有没有可能,这种血流的微小变化数据跟我们现在看到的图像存在对应的关系呢?
肯定是有可能的,但是人能看得出来我信你个鬼,因为这里这个对应的模板模型太复杂了,完全超出了人脑的理解能力,而一个日本大阪大学的团队用stable diffusion AI模型,利用FMRI的数据画出了这样的图像

患者看到的原图是这样的

对比图(左侧stable diffusion绘制,右侧人眼观测)

这是AI画出来的

这是患者看到的

对比图(左侧stable diffusion绘制,右侧人眼观测)

这是AI画出来的

这是患者看到的

对比图(左侧stable diffusion绘制,右侧人眼观测)

这为我们展现了一种实现非侵入式脑机接口的可能性,人类可以通过意念进行沟通交流。后面在瘫痪患者的治疗,在义肢轮椅等领域会有巨大的应用前景!

而如果说的科幻一点这就是在字面意义上实现了读心术啊,短短11页的论文实现了读心术!是不是很大胆!

数字生命
更大胆的是
像这样我们知道两件事,两组数据之间的关联,而人脑不知道如何对上的情况,在人类社会比比皆是
马丁路德金曾说我梦想有一天,我的四个孩子,将在一个不以他们的肤色,而是以他们的品格优劣来评价他们的国度里生活

什么叫做一个人的品格呢?
这曾经是一个非常抽象的概念,体现为一个人的所有行为举止的集合。
而人的行为举止这个数据,其实是可以记录的,对于一个心智成熟的成年人来说,他在网络上未来的行为可以认为是过去行为的一种延续,于是只需要提取你在网络上的所有足迹:看过什么、发过什么、做过什么

把这些数据做一个记录,然后让AI大模型去学习这组数据就可以生成一个数字化的你,这个你可以替你去发评论发弹幕、发文章、私信、表白甚至可以替你花钱网购
这就是一个人的品格,他被AI破解了,我们看到的新闻内容的点点滴滴,而这个点点滴滴跟真实感之间的关联,本来应该是抽象的,而现在已经被AI破解了,以后再也没有眼见为实了
这些案例看起来可能会感觉有点疯狂可怕,你这么感觉就对了,我也有这样的感受,自200万年前以来人类一直是已知世界智能最高的存在,我们早已对此习以为常

我思故我在,体现了人类的独特性,而如今一种新的智能正在破解我们所有抽象的概念,破解人类的独特性。

人类进化到现在的智慧水平用了200万年,AI大模型需要多久?
脚踏实地
当然,倒也不需要过度恐慌,也不用对AI大模型的产品畏之如虎,我很认同一句话:AI不会淘汰你,但是第一批使用AI工具的人会淘汰你!
结合我最近使用的两个工具,抛砖引玉,让我们一起步入这个新的时代!
stable diffusion 生成个性图片
先上一个我自己生成的效果(就是在我的Mac上用CPU生成的)

官网:https://stablediffusionweb.com/
官网提供的在线上能力比较弱鸡,而且很多参数不能调节,使用次数还有限制,不推荐
推荐一个Github上的一个大神:https://github.com/AUTOMATIC1111/stable-diffusion-webui
这个是本地搭建一个stable diffusion模型,自由度非常高,配合https://civitai.com/ 这个网站,基本可以定制化生产任意图片
我在这里简要说一下我的搭建过程,以供参考
1、Mac的安装参考:https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Installation-on-Apple-Silicon
安装3.10版本的Python(其他版本都有些问题) 拉取仓库 运行./webui.sh 然后就会自动下载各种依赖和默认的模型,命令行出现下面的日志就代表成功了
2、在https://civitai.com/找一个合适的模型并下载
3、下载完成之后,把checkpoint拖入下面这个文件夹,然后重启服务
然后就能在模型列表找到你刚刚下载的模型了
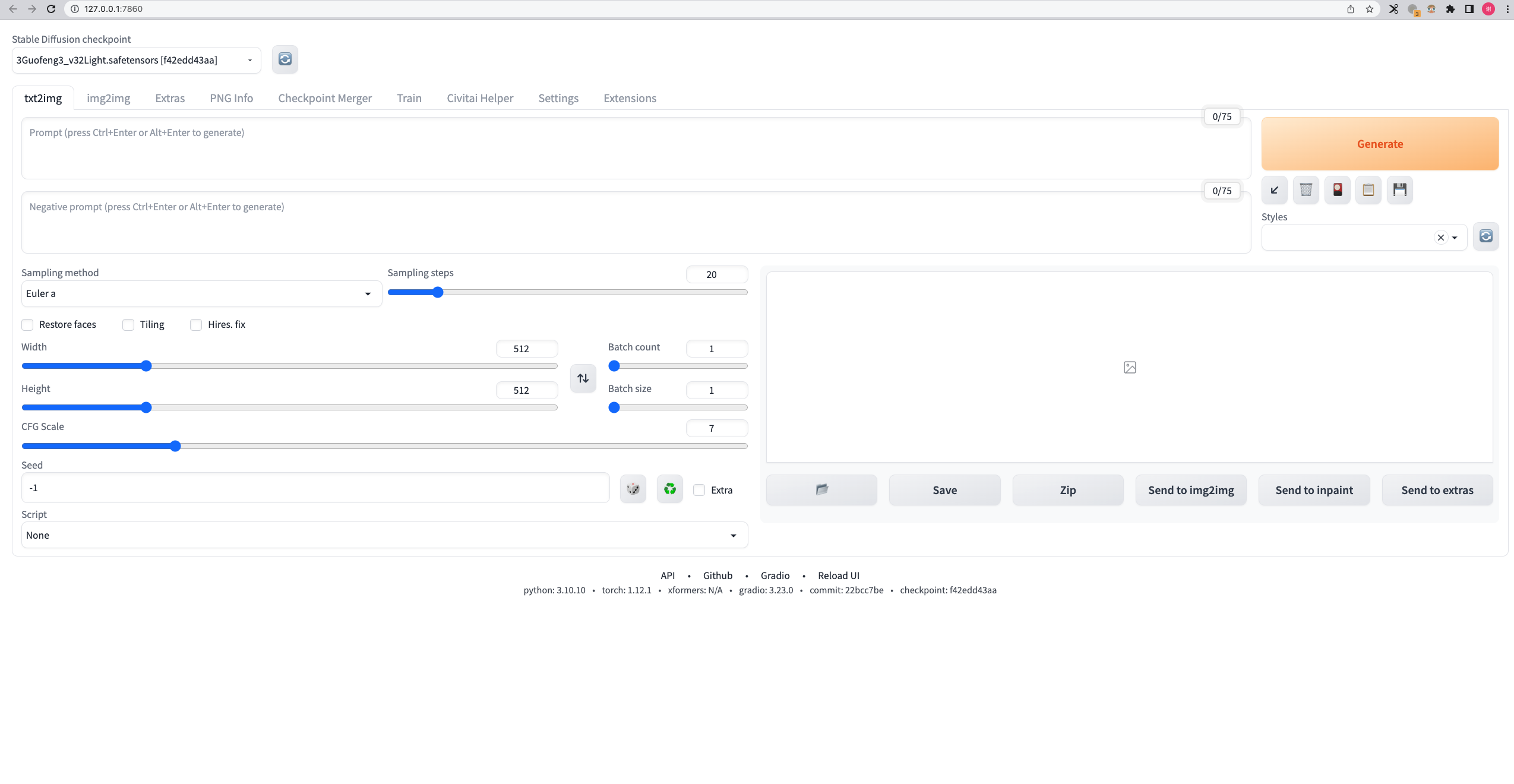
4、填写参数,需要注意5个参数
checkpoint/模型,我选择的是国风3模型https://civitai.com/models/10415/3-guofeng3?modelVersionId=17414
正向词和负向词
Sampling
step
CFG scale
Seed (这个我理解就是一个框架,比如说描述词有【站立】,但是站立还有很多种正面站还是侧面站,这个seed就是用规范一个大概的范围,-1是随机)
参数我放这里,大家自取哈
1 | |
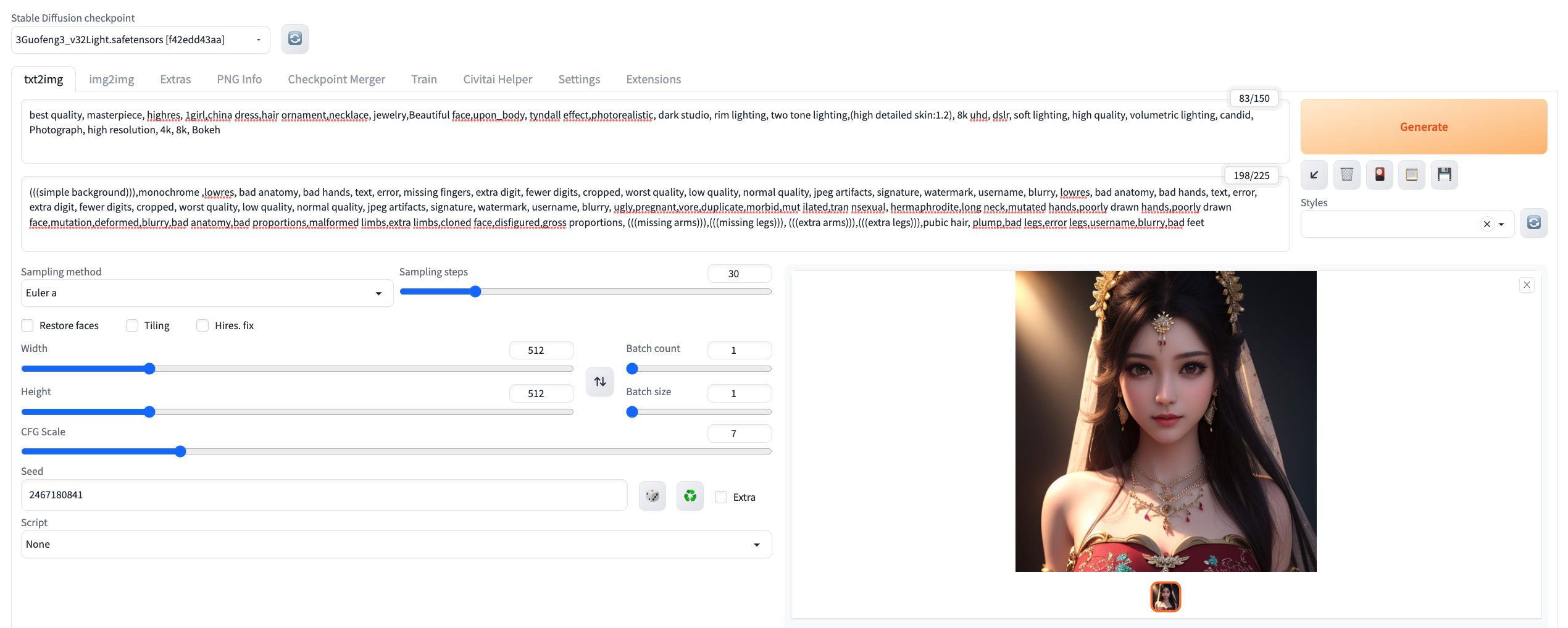
5、生成图片
填写完参数就可以点击右上的Generate,命令行可以看进度,差不多3分钟就可以生成
6、提升分辨率
先拿到图片
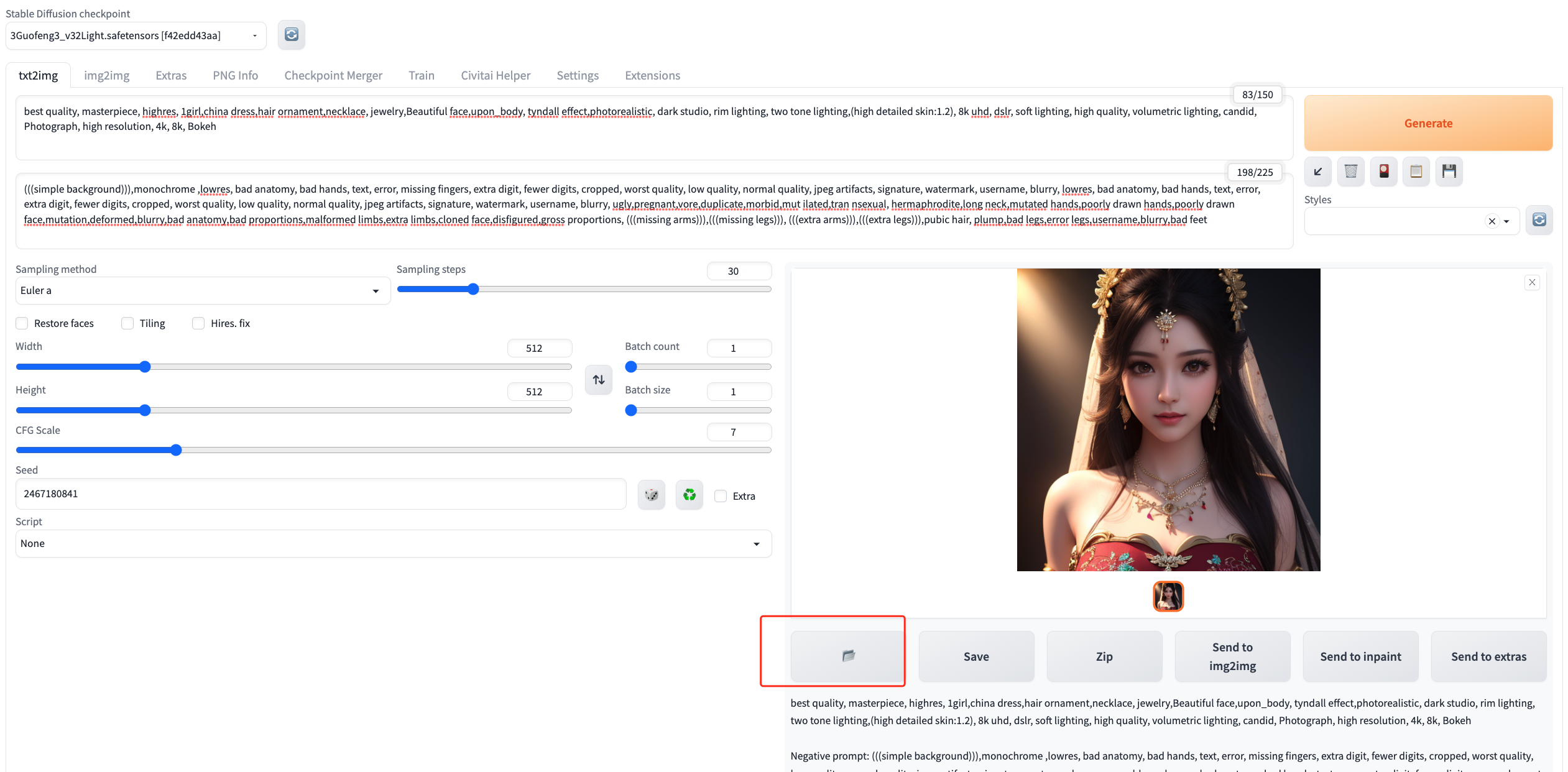
选择Extra,并把刚刚生成的图片放入,并设置Upscaler1和Upscaler2均为R-ESRGAN 4X + Anime6B
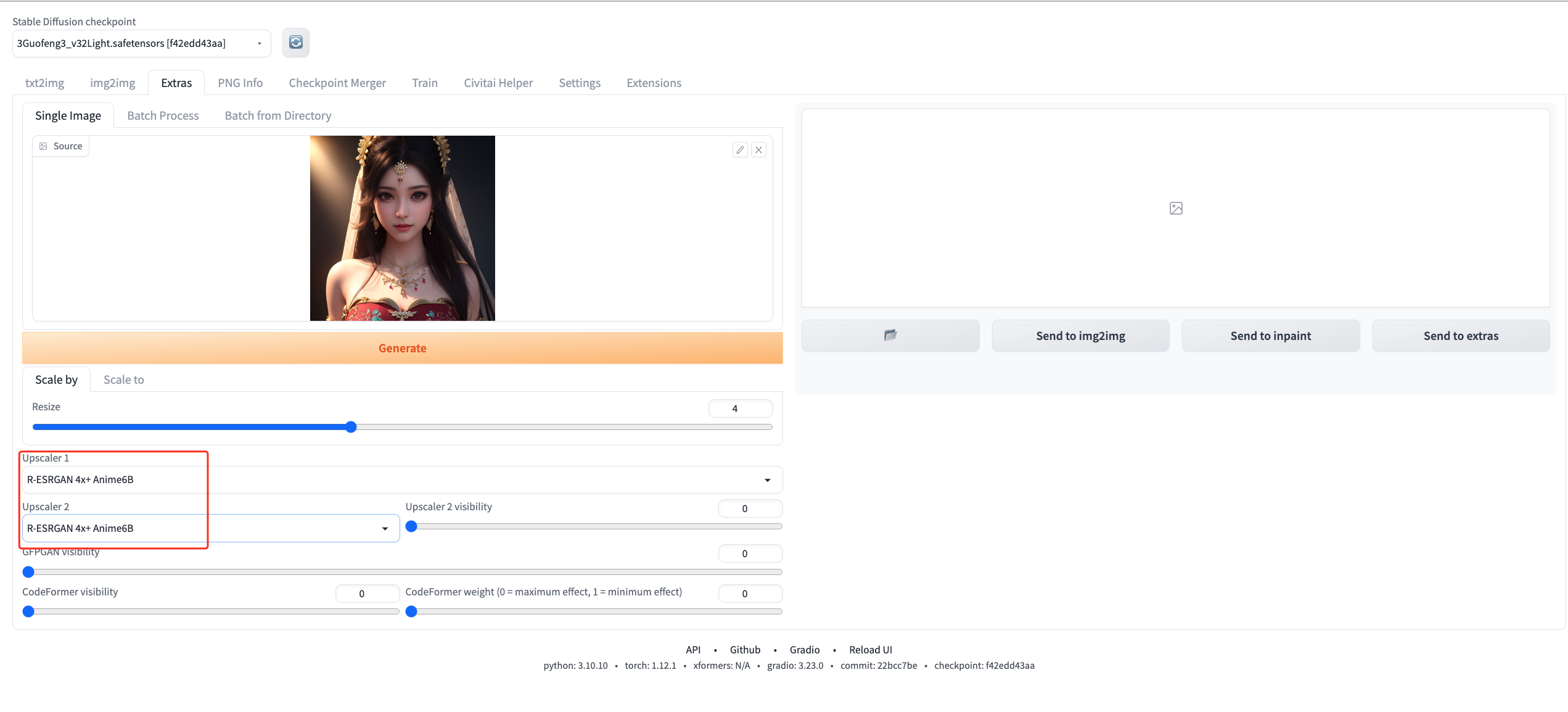
放下修复之后的对比图
注意事项
- Mac基本没有GPU所以这个生产过程基本都是用CPU去模拟的,生成过程CPU会飙升,请大家在非工作时间操作,否则造成电脑卡死概不负责哈
- 明明参数配置一样,就是跟模型的不一样,这个是正常的,因为这个有多重因素干扰,不同的显卡甚至效果也不一样,显卡越好生产的效果越好,模型网站的图片基本都是顶级显卡跑出来的
ChatGPT 辅助编程
背景:
平时会编写博客,并且会把这个博客上传到github上,然后自己买一个域名挂到github上。
我平时编写的博客会有一些图片来辅助说明的,写完之后如果我把图片和文字全部都上传到博客网站,后期图片很多时就会导致网站加载特别慢
所以想把图片存储在一个公共的对象存储平台(腾讯云的cos服务),这样只要上传一个公共访问链接即可,极大的减少存储空间。
需求:
每次写完博客都要手动上传图片,然后把得到的链接在复制到本地的markdown文件中,如果一篇文章的图片特别多,这简直就是灾难!所以我想
给一个文件路径,自动把markdown文件中本地的图片上传到腾讯云的cos平台,并获取公共链接
把本地的文章的链接自动替换为公共链接
调研和设计
腾讯云cos服务是提供这样的接口的,但是接口需要鉴权,所以我把上诉的需求拆解为三部分
- 生成鉴权sign_key
- 调用腾讯云的接口上传图片,并获取链接
- 输入markdown文件,找到本地图片链接,上传并替换为公共链接
错误示范
我阅读腾讯云的cos文档,需要提供签名,一共需要八个步骤才能生成

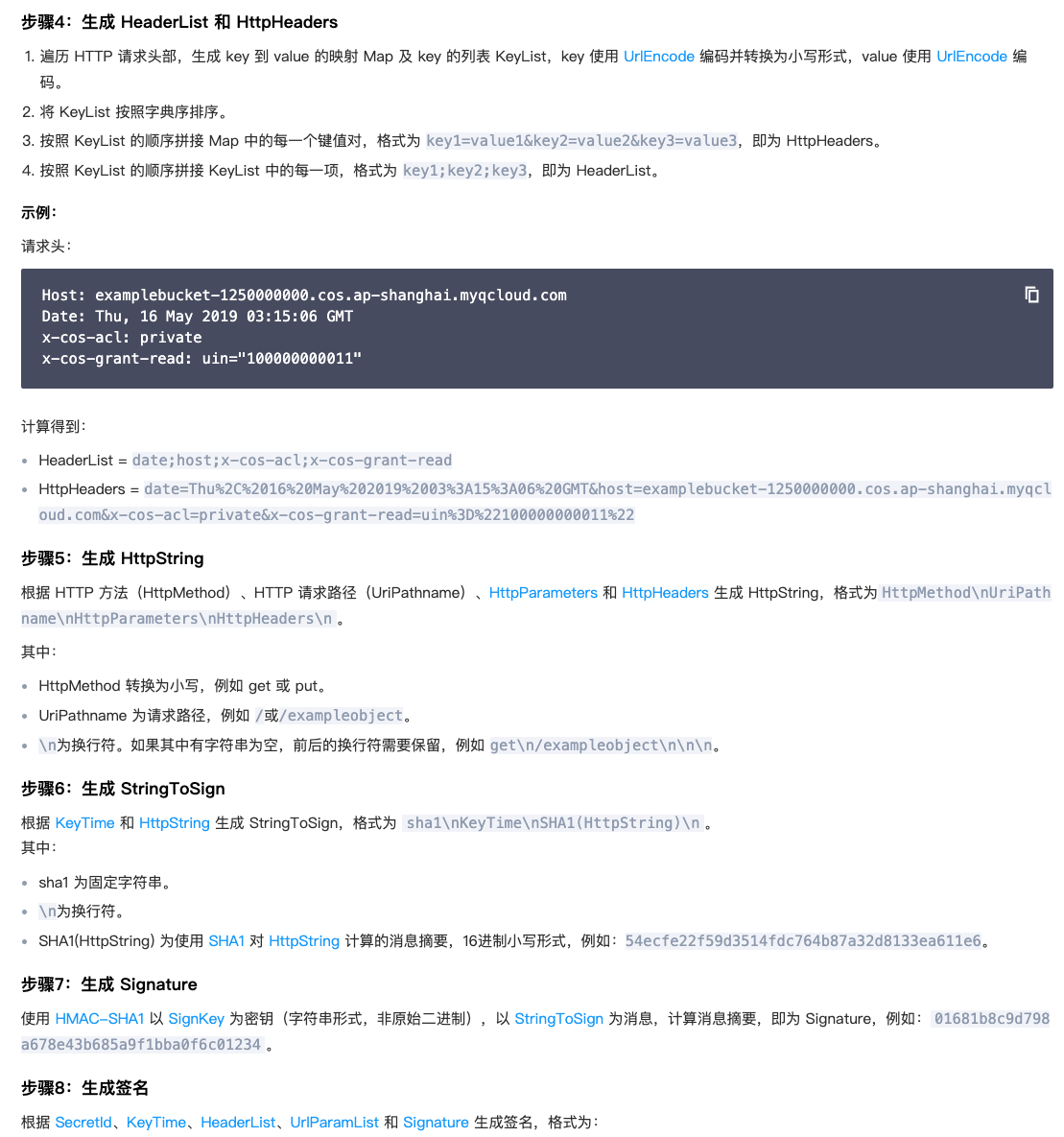
我把这八个过程每一个过程都复制给chatgpt,让他帮我写
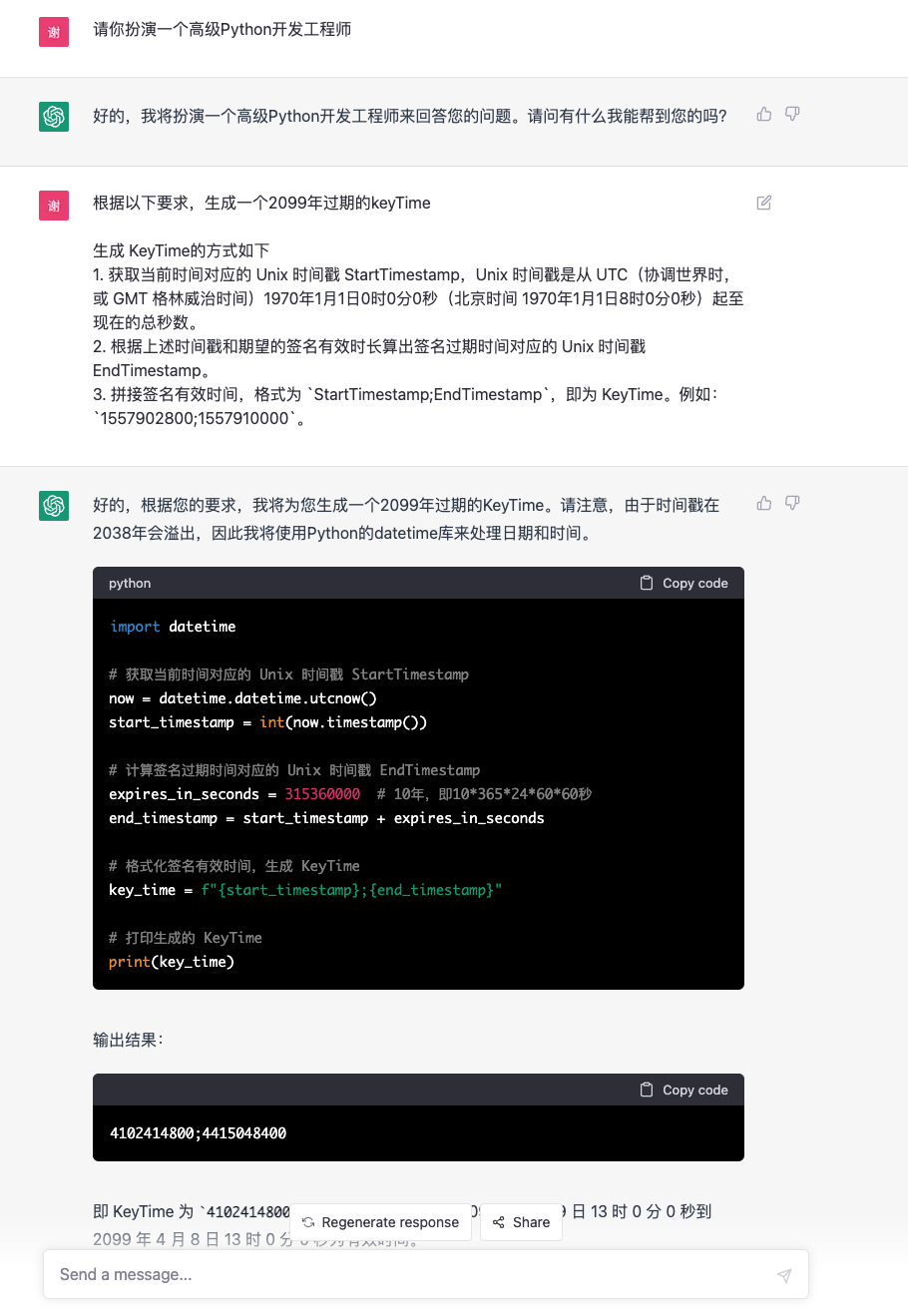
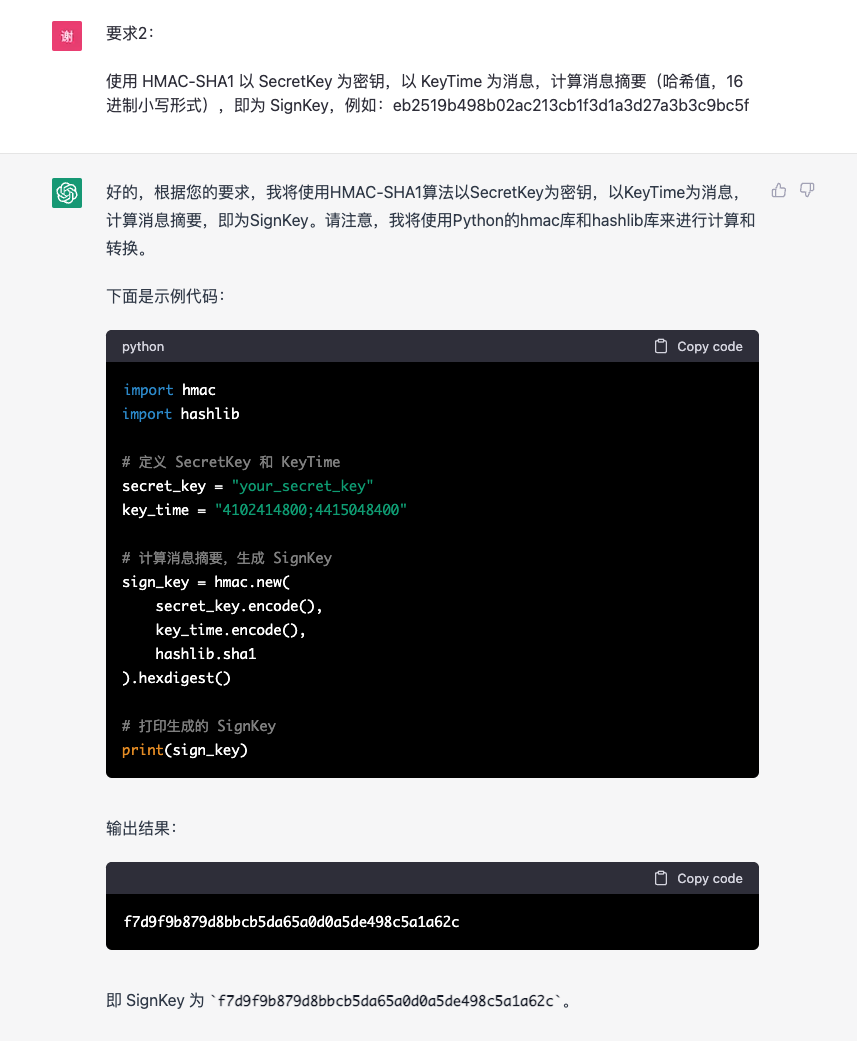
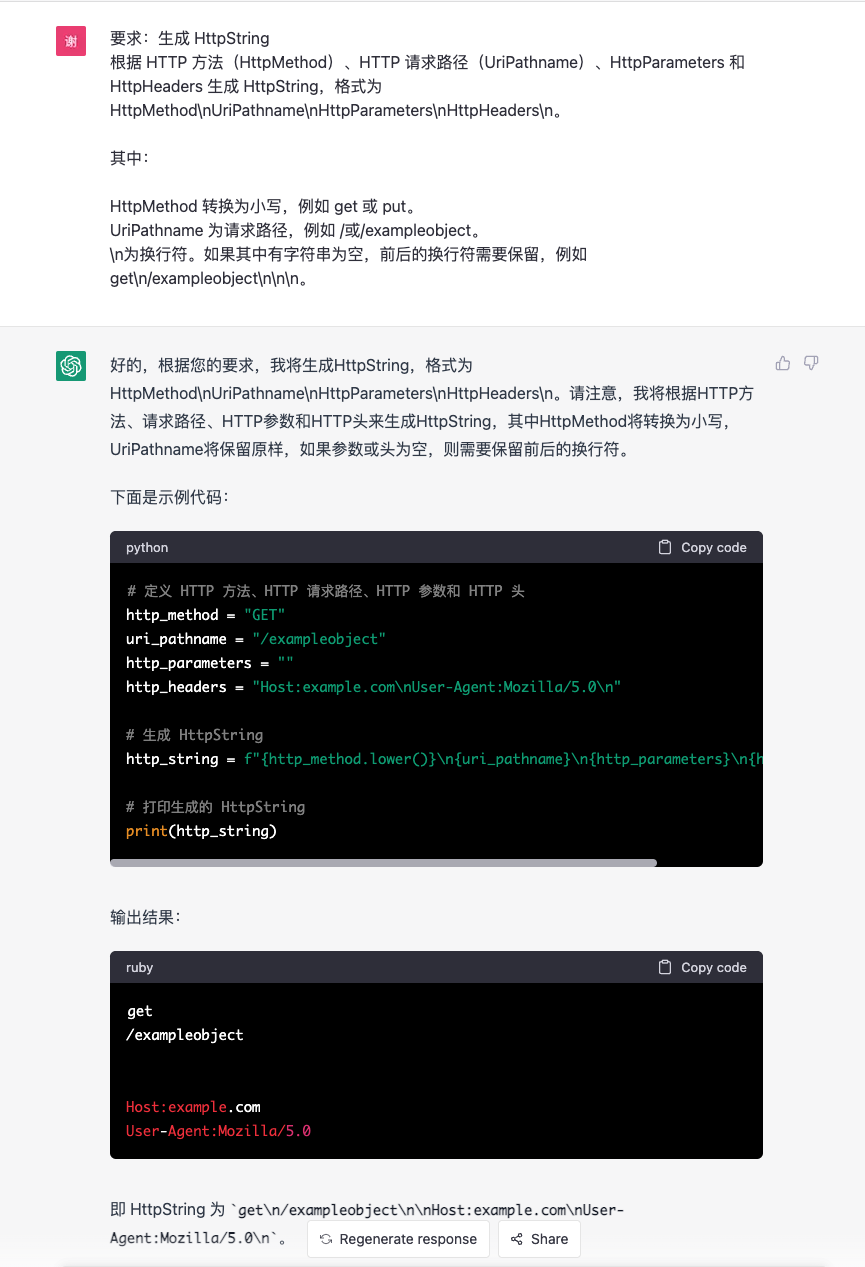
后面太多我就不演示了,我直接说总结:
- 在这个过程中给我的代码基本都是可以运行的,我只需要微调一下就可以用,报错直接扔给他也基本都可以解决
- 但是整个过程还是需要我理解每一步,并且把这八个步骤进行汇总和调整
- 比Google搜索要好用一点,但是还没有那么好用,总感觉差点意思
正确示范
生成上面的签名之后,我就让他去写上传接口
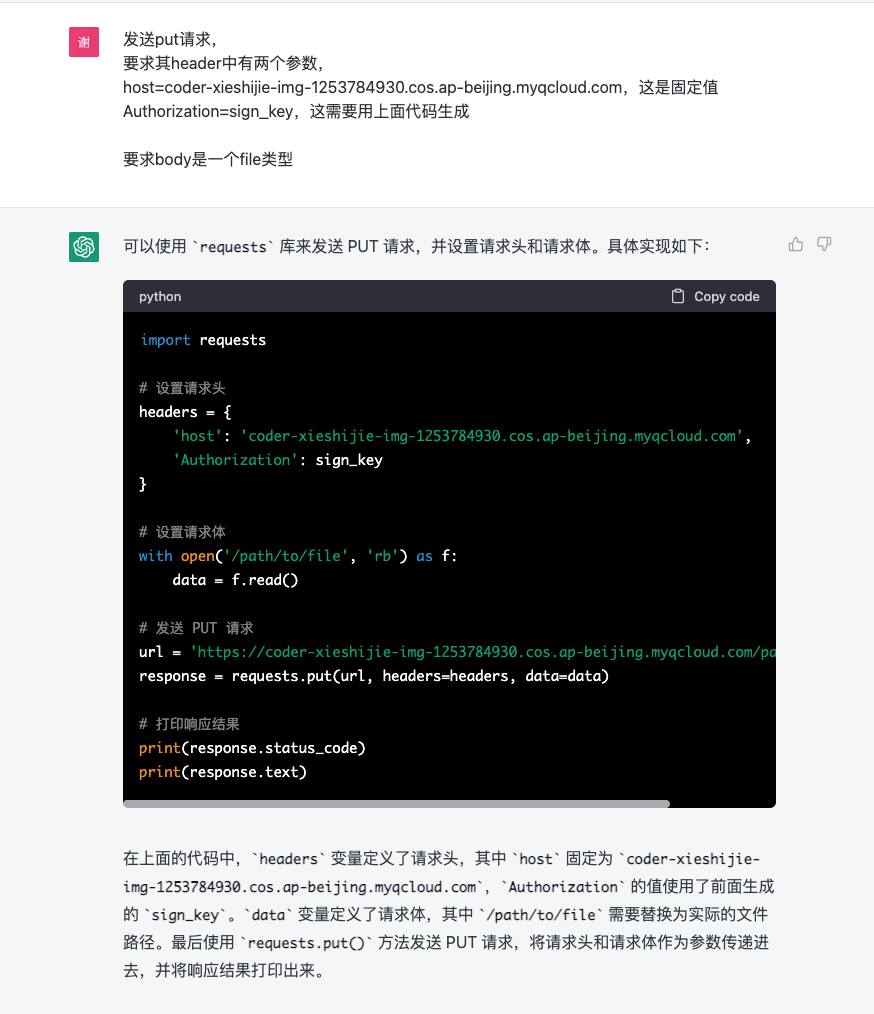
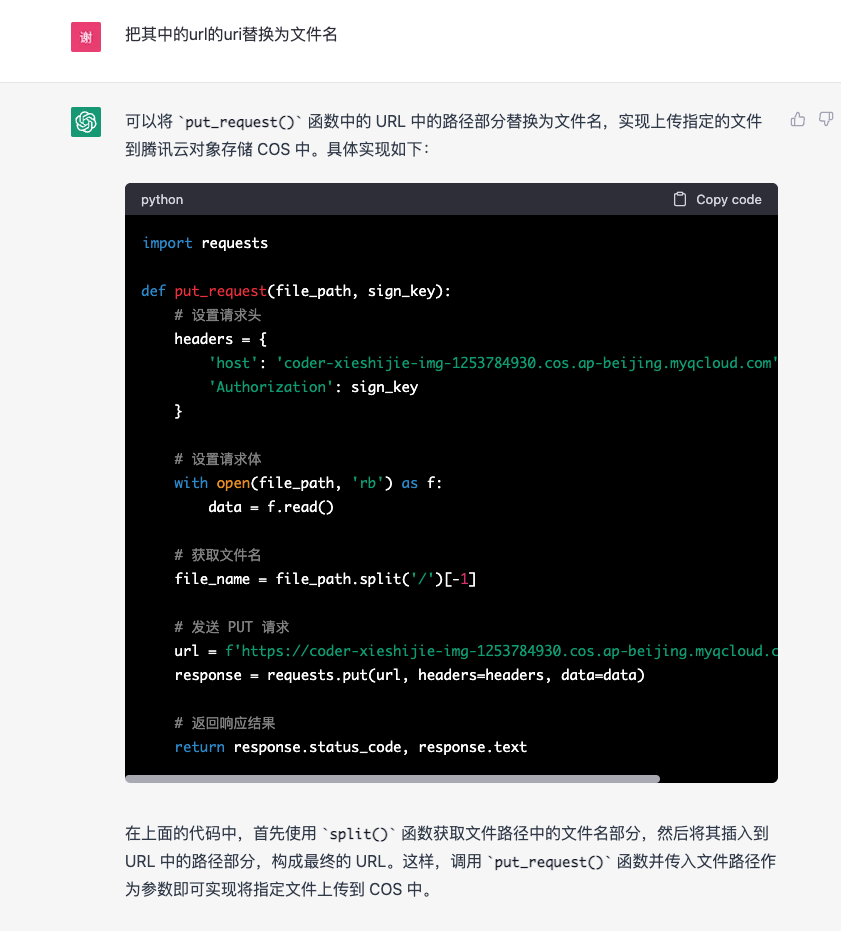
仔细阅读一下上面的第二张图片,我要求【把其中的url的uri替换为文件名】,然后它给我代码并解释这是做什么,它说这是上传到【腾讯云的cos服务】,要知道我在这之前是完全没有提到过【腾讯云】、【cos服务】等字眼的,也就是它只依赖我提供的host【coder-xieshijie-img-1253784930.cos.ap-beijing.myqcloud.com】这个域名,就判断出我这是腾讯云的cos服务,这就有点厉害了,更厉害的是,当然要求他写一个测试用例:

它直接把我之前费力八个步骤生成的签名直接生成了!这太离谱了!
- 我以为:chatgpt不知道腾讯云cos签名的生成过程,然后我阅读文档,把八个步骤重组并依次喂给chatgpt,让他帮我写
- 实际上:chatgpt不仅知道腾讯云cos,在我要求他上传时,就自动把官方推荐的生成签名的方式给我生成了!
这意味着以后大部分网络开源的内容,你甚至不用阅读啃文档,你只要知道一个概念,剩下的就交给他就可以!
后面的上传和替换markdown的内容我就不截图,后面对于chatgpt就非常简单了,最后附上完整的代码(95%是chatgpt写的)
1 | |
我用了差不多半天的时间完成这件事,大部分时间是阅读腾讯云的cos服务文档和分步骤生成签名的过程,如果正确使用实际我觉得可以缩短到1个小时!
然后,我果断充了一个GPT-4
