Gitlab redis多AZ容灾高可用方案调研
背景
Gitlab多AZ容灾建设,目前自身服务已实现单AZ故障演练服务秒级自动切换恢复。但对应Gitlab依赖的服务平台,还有redis没有完全参与AZ容灾演练,AZ容灾效果仍处于未知状态。
问题
- Gitlab****只支持redis哨兵模式,不支持redis cluster mode
- 公司redis集群哨兵模式不支持AZ逃生,且后续暂无计划支持。
- 现状问题是AZ故障时,可以确保Gitlab服务正常,但故障恢复后的短暂时间(预估2~3min)会有redis双写问题
问题现状分析
经过调研和梳理,之前gitlab服务所在AZ和依赖redis所在AZ情况,整理如下场景:
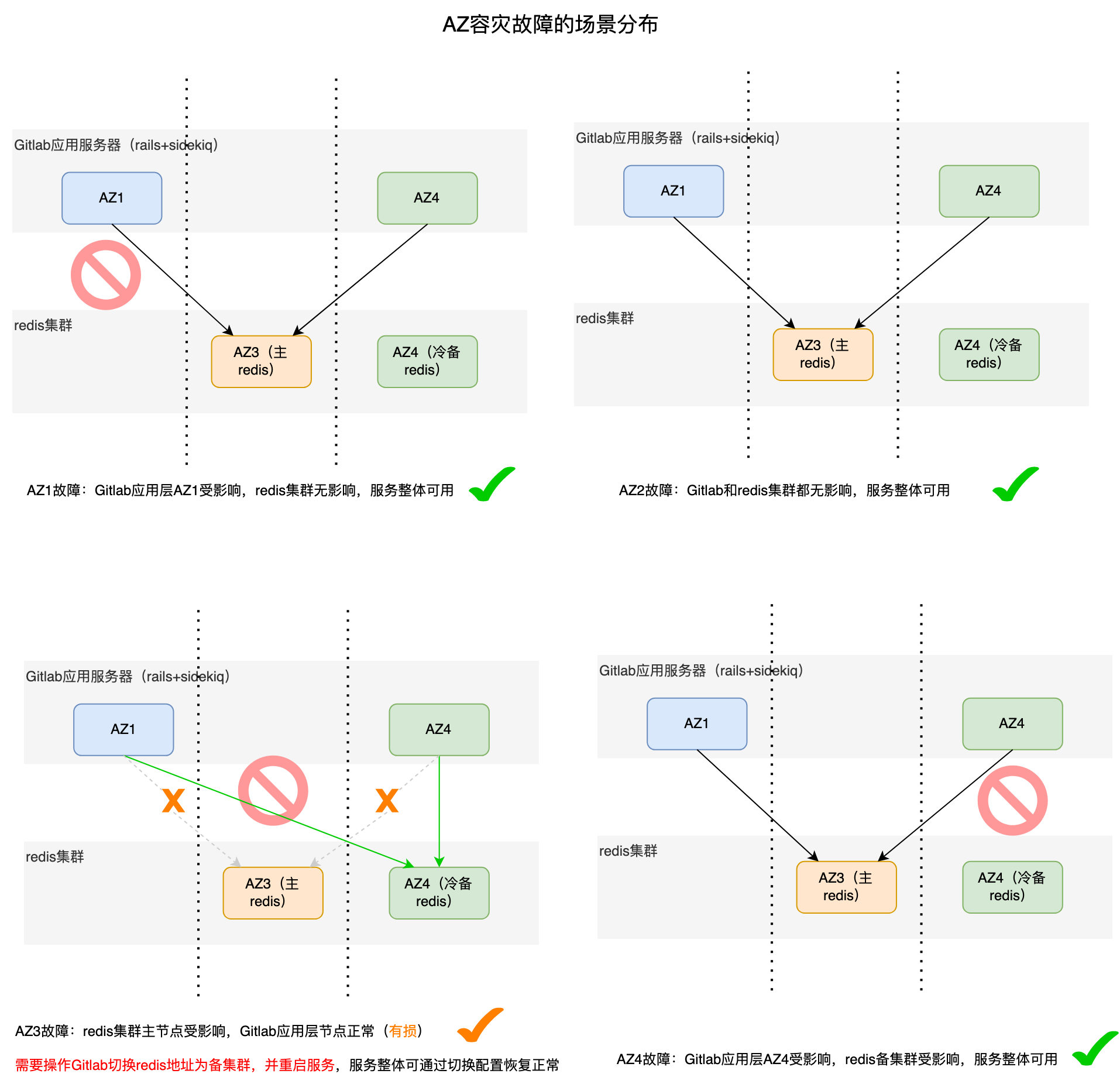
综上,如果是按照AZ2.0架构,进行多AZ容灾建设,如果是单一AZ故障的话,Gitlab可以通过一些低成本的逃生手段达到AZ故障逃生,进而正常提供服务。
但如果通过AZ容灾演练,redis主节点发生变化,即****redis主节点和gitlab应用服务器在同一AZ时,就会出现问题
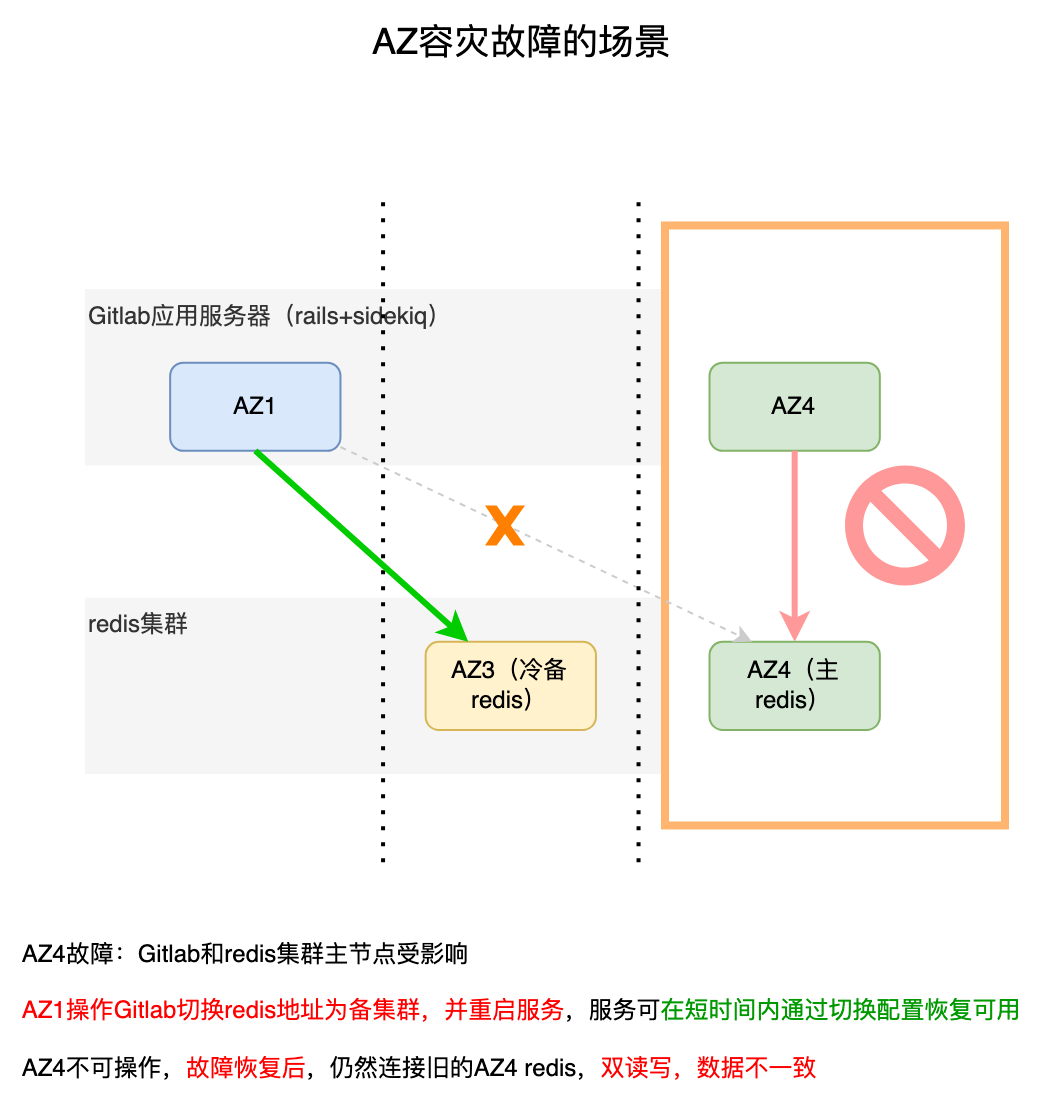
上述故障切换第3种情况,若故障恢复后,AZ4连接还是之前的AZ3 redis集群,AZ1连接的是新的AZ4 redis集群,在对故障AZ4的Gitlab服务进行修改之前的这段时间(故障时所在AZ的Gitlab服务器无法登录和操作),此时可能会出现reids双写,数据不一致的情况
业界调研
Gitlab redis社区方案是使用redis sentinel模式,未给出有相关多AZ可用区的建设参考方案。Gitalb不支持redis cluster模式,Redis Cluster mode is not supported by GitLab.
gitlab.com使用的推荐方案是使用第三方云服务提供商,自身可不用考虑AZ容灾的问题,交给云服务提供商解决。
各大厂redis容灾方案调研
| 快手 | Google cloud platform | 阿里云 | 腾讯云 | |
|---|---|---|---|---|
| 架构部署 | 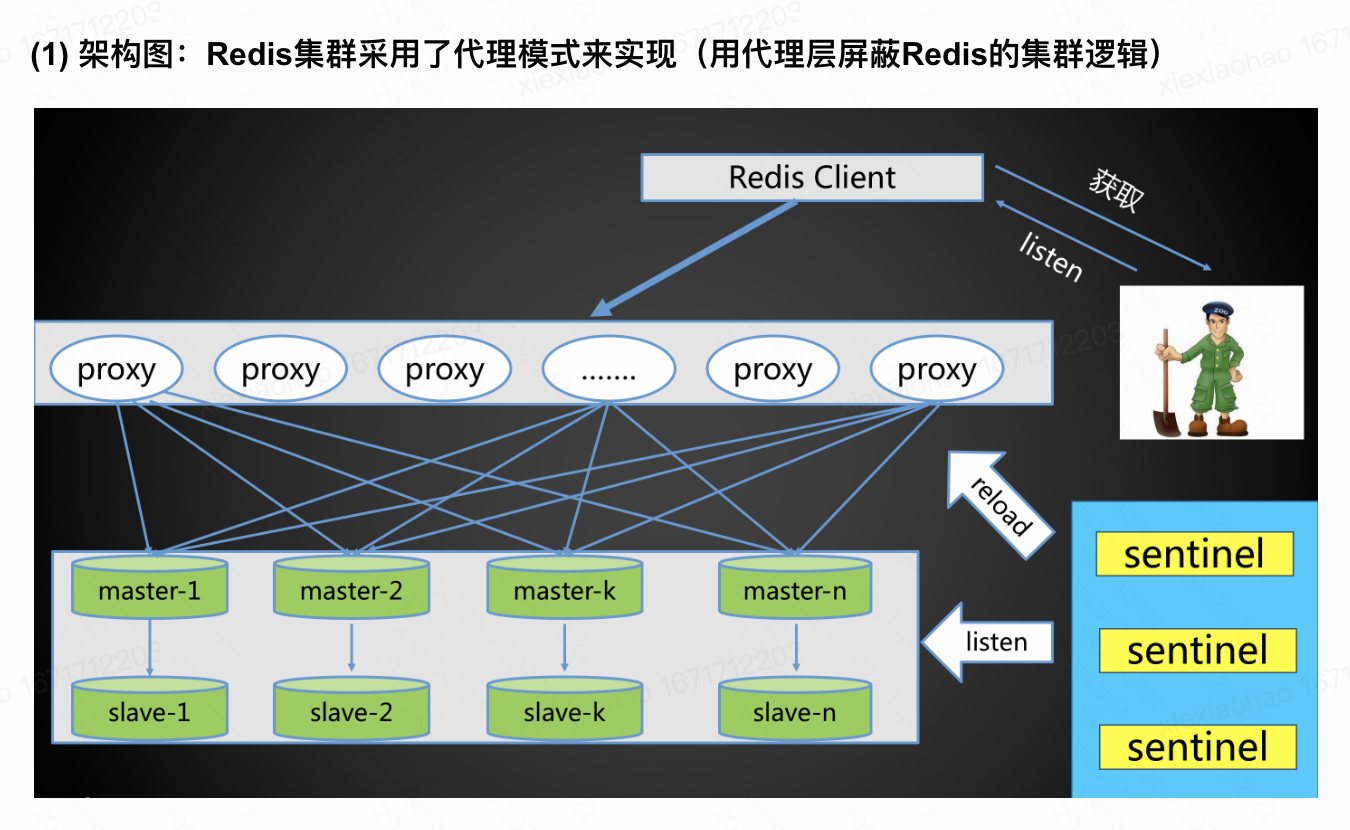 |
Memorystore for Redis 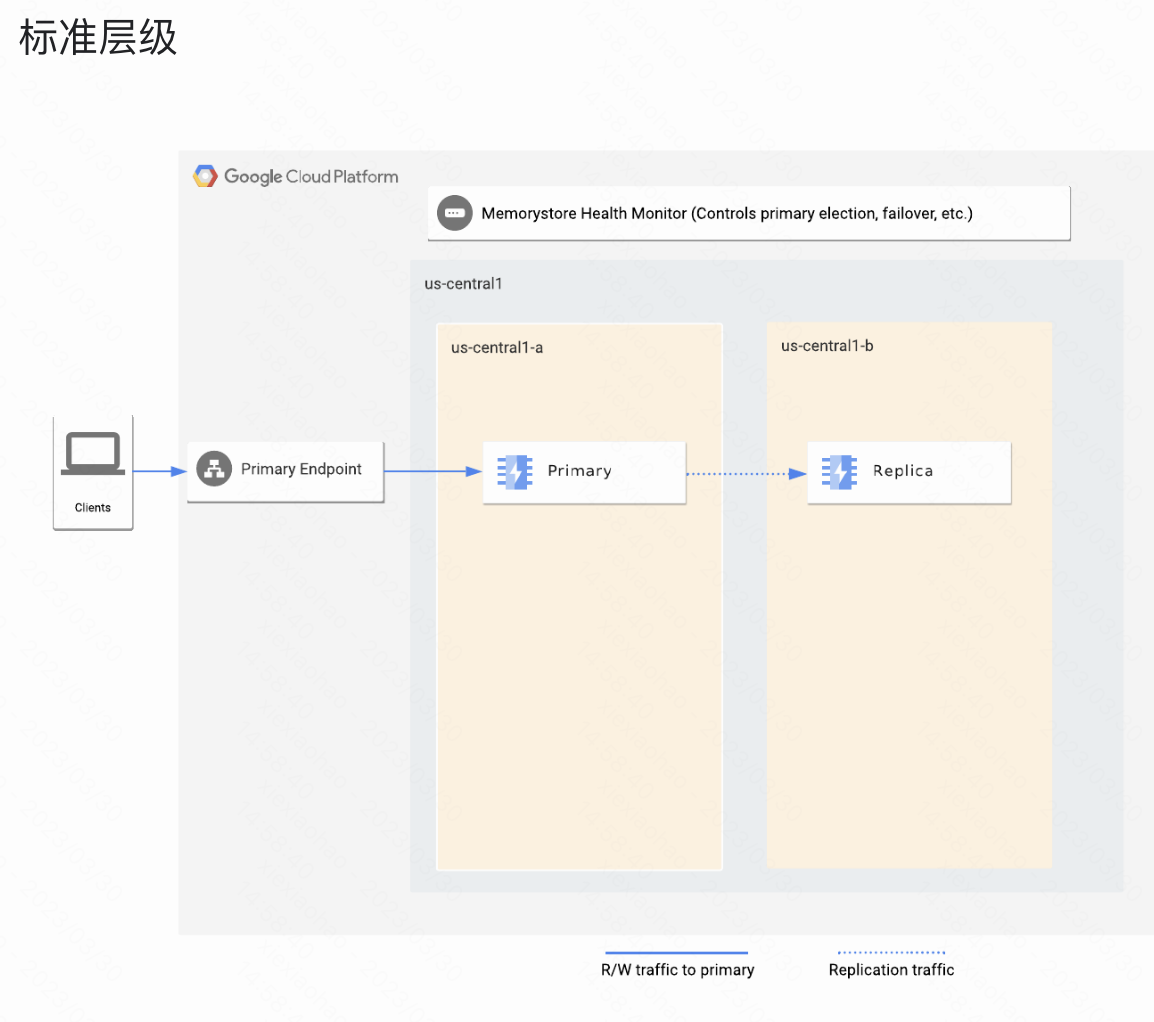 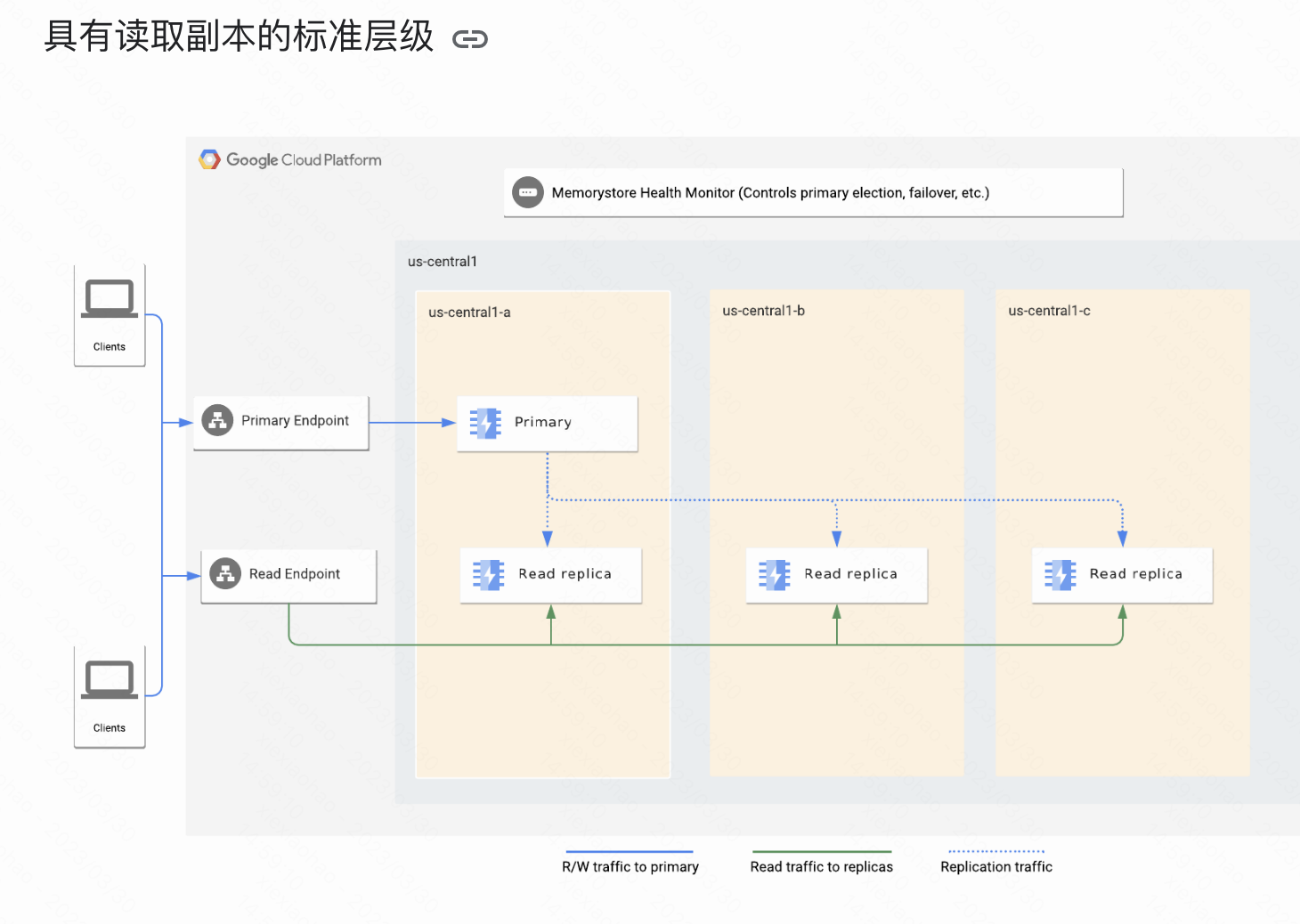 |
集群架构1.代理模式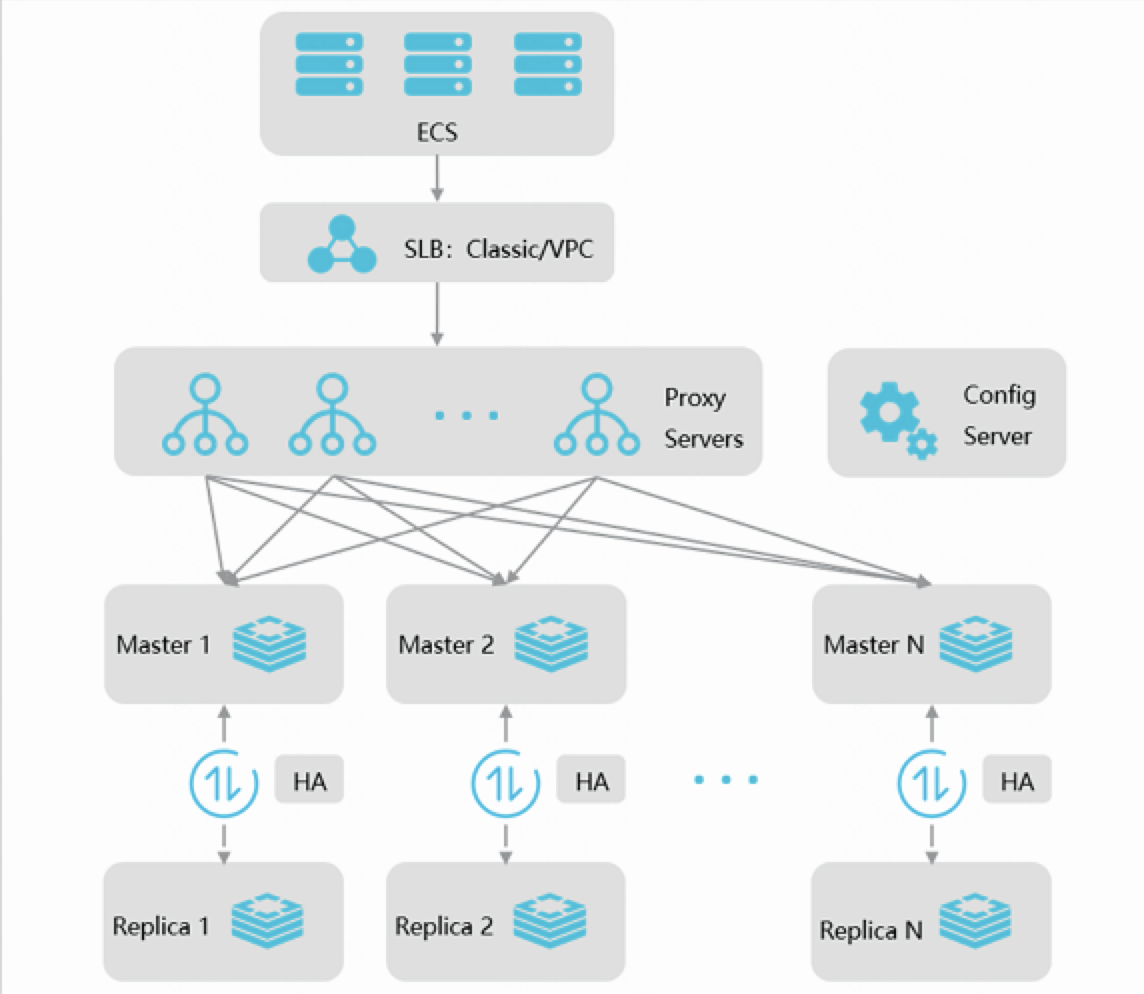 2.直连模式 2.直连模式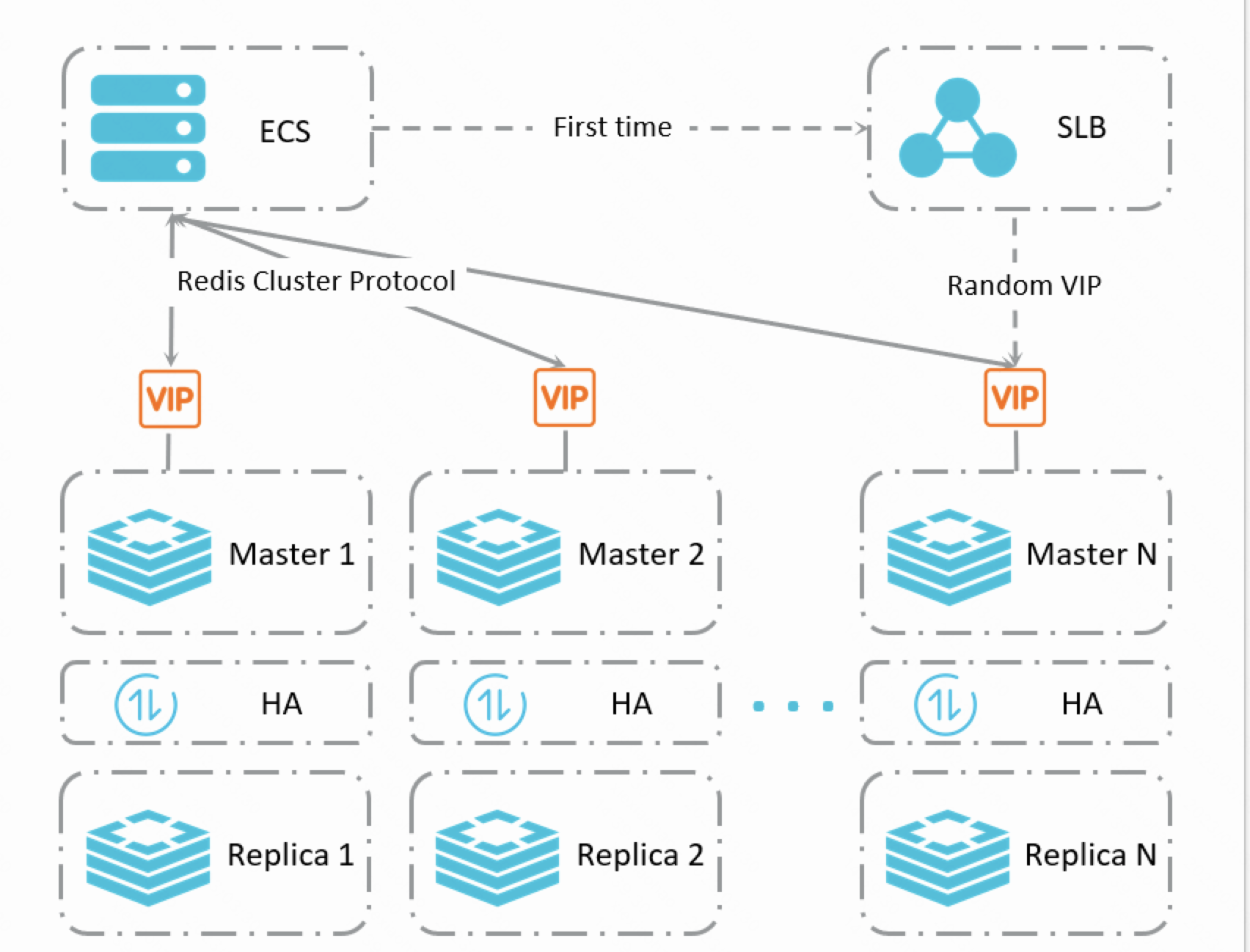 |
集群架构 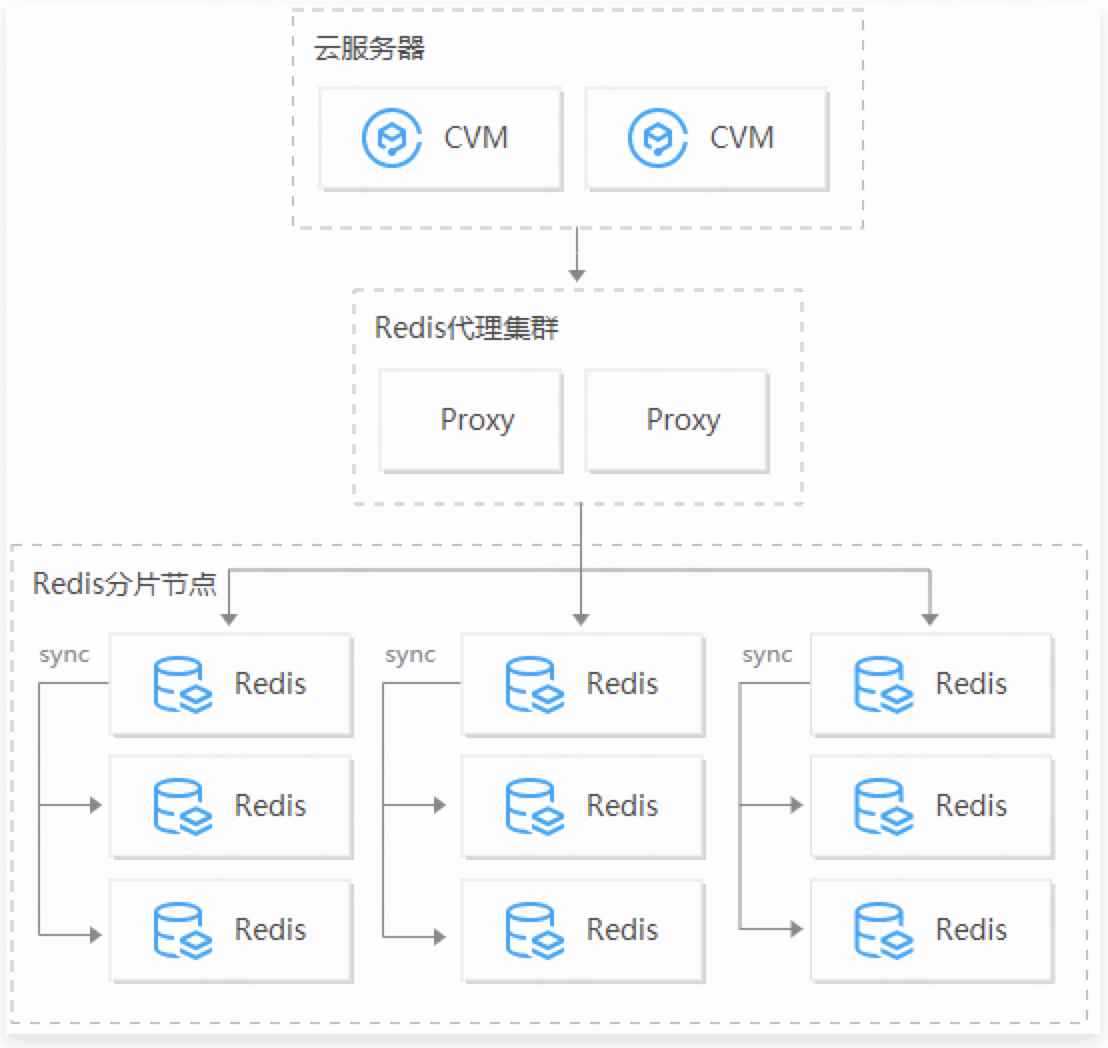 |
| 容灾方案 | 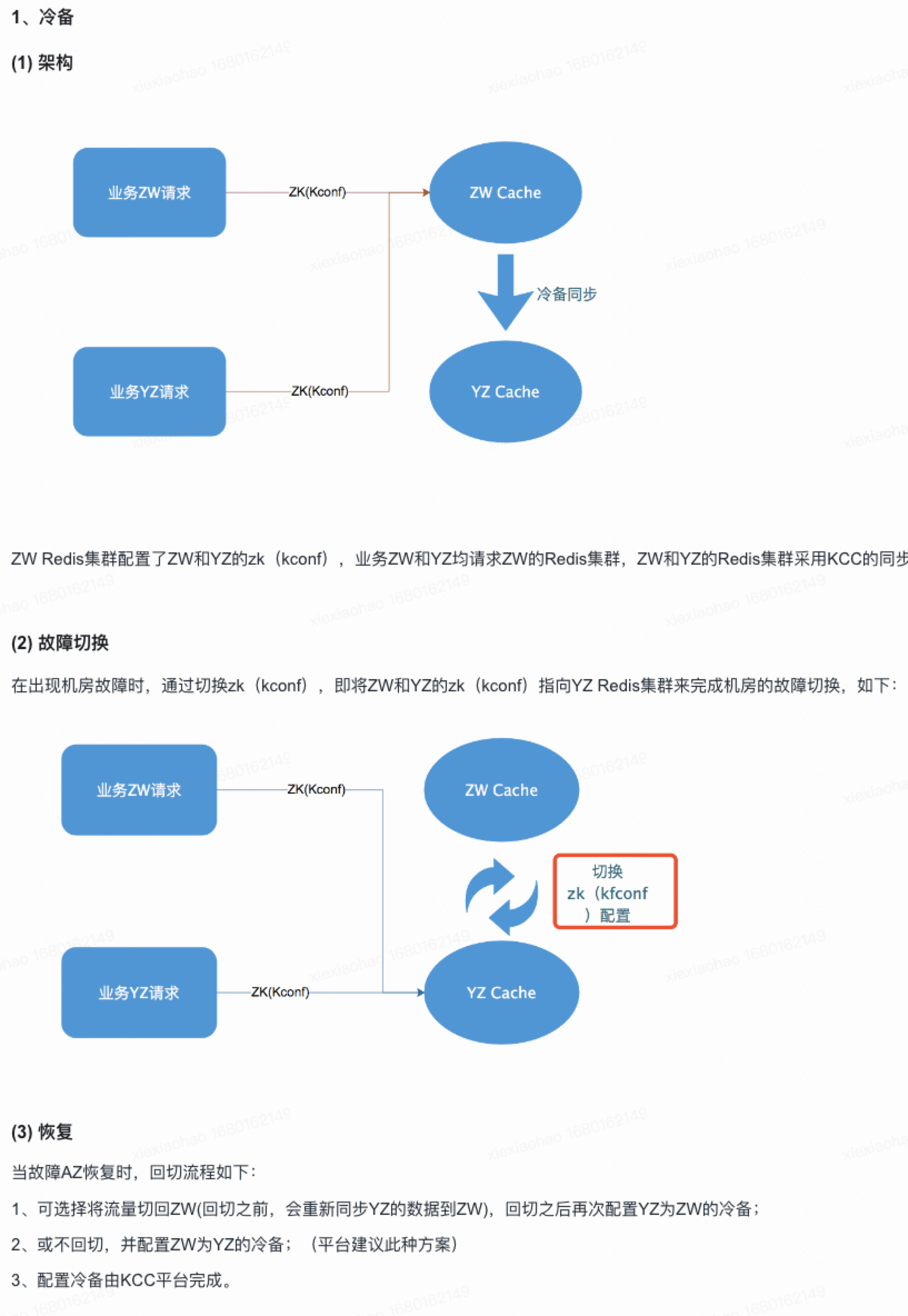 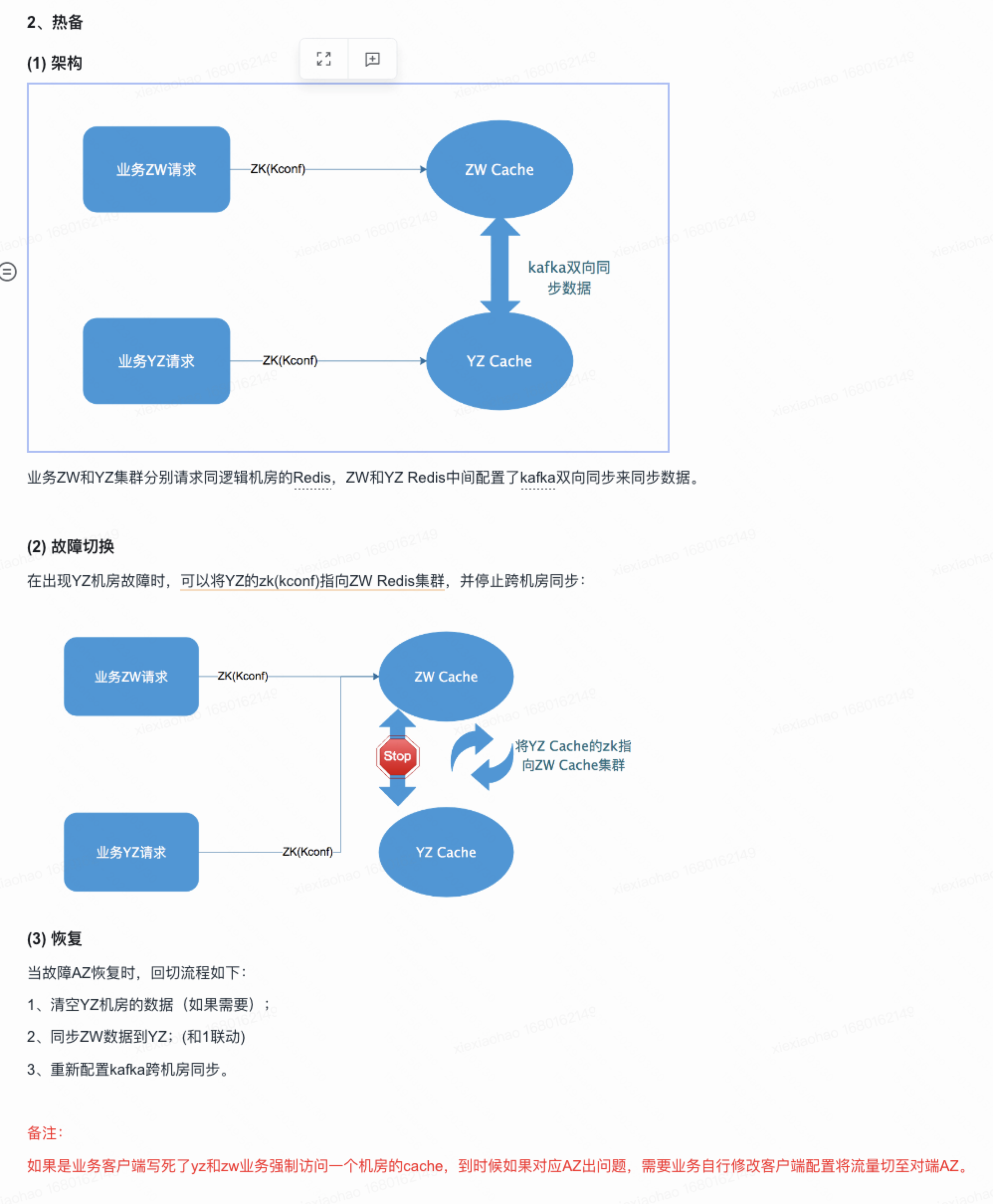 AZ2.0 AZ2.0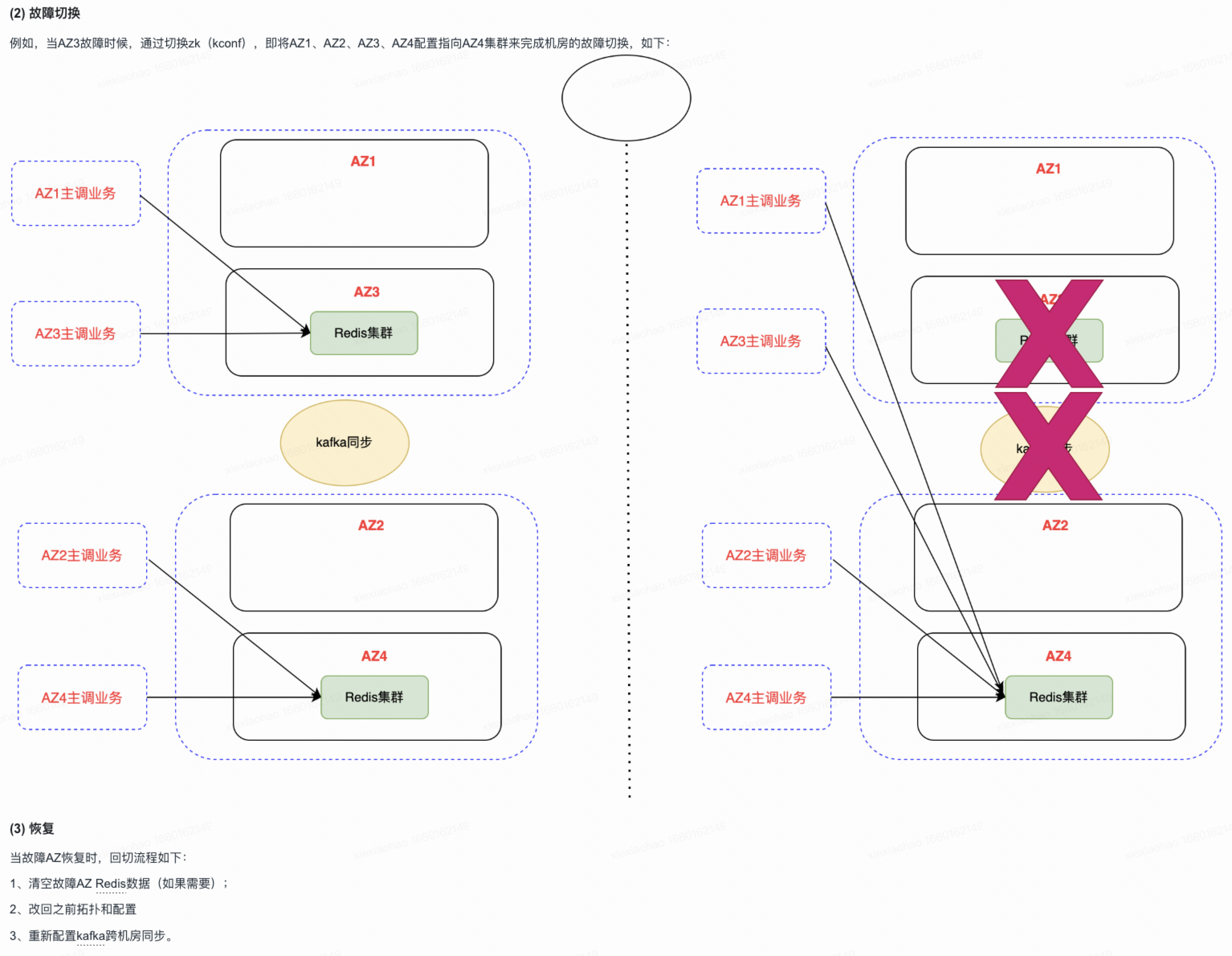 KCC平台AZ逃生前提条件:使用公司框架****没有写死ip地址情况(需要业务自行修改客户端配置切换AZ) KCC平台AZ逃生前提条件:使用公司框架****没有写死ip地址情况(需要业务自行修改客户端配置切换AZ) |
跨地区复制读取副本允许分布式读取 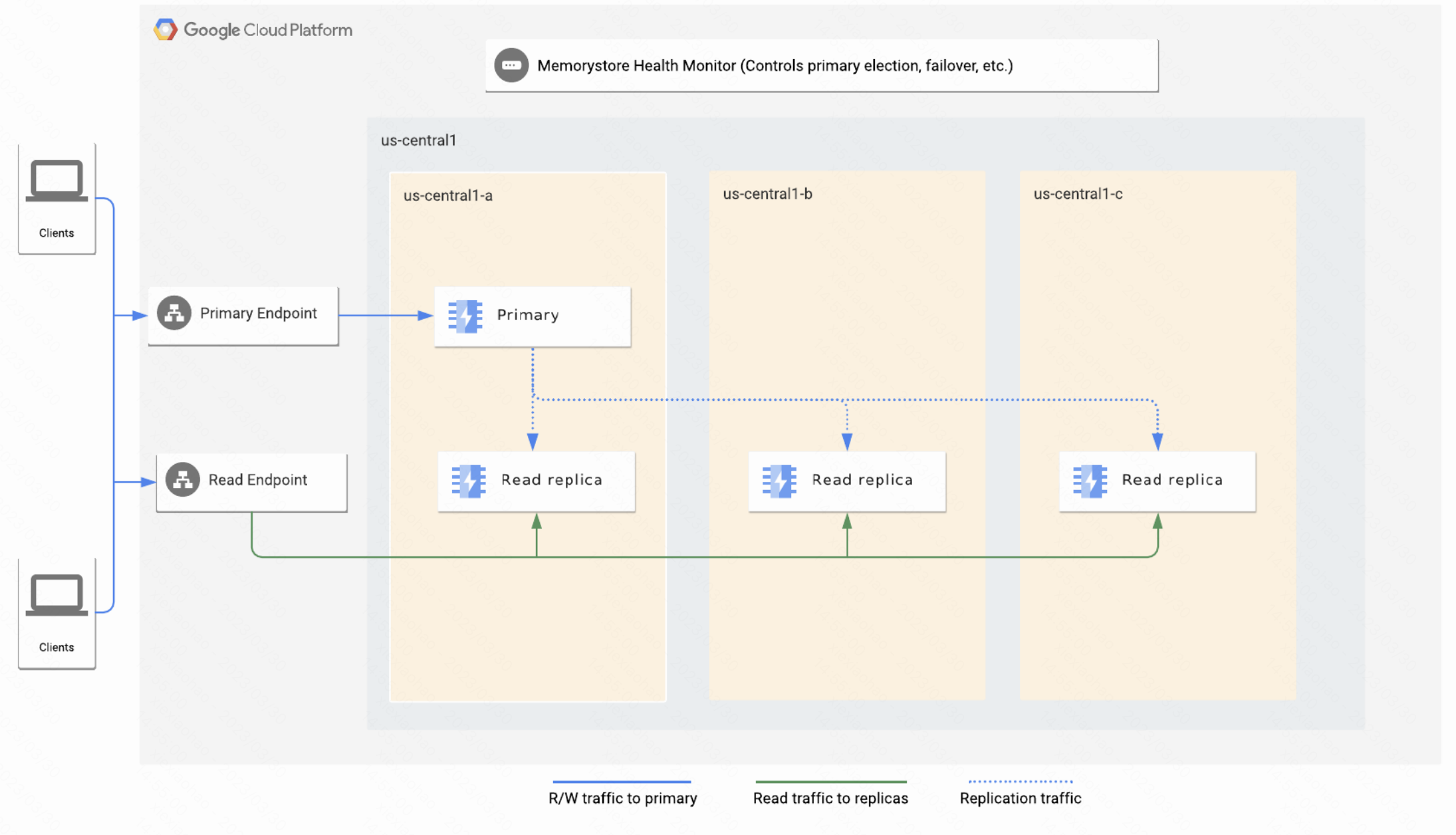 |
单可用区高可用方案同城容灾方案跨地域容灾方案 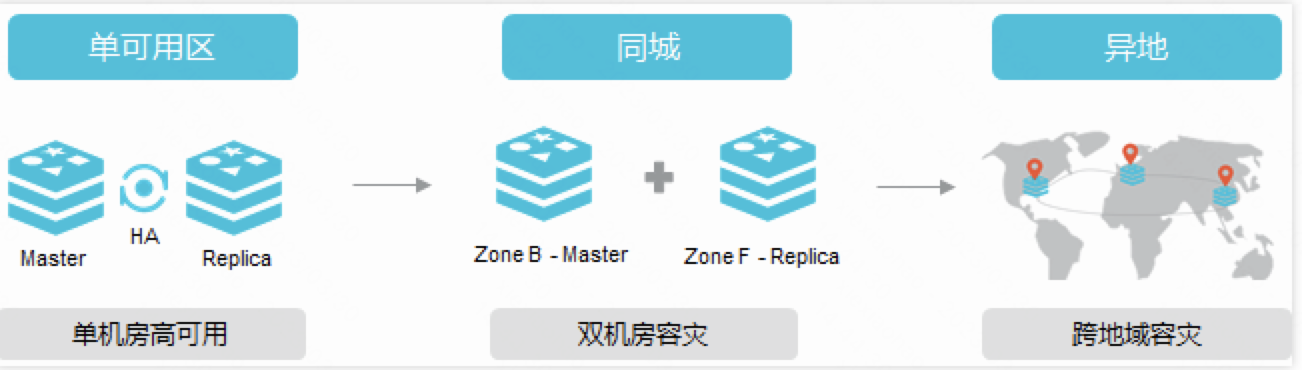 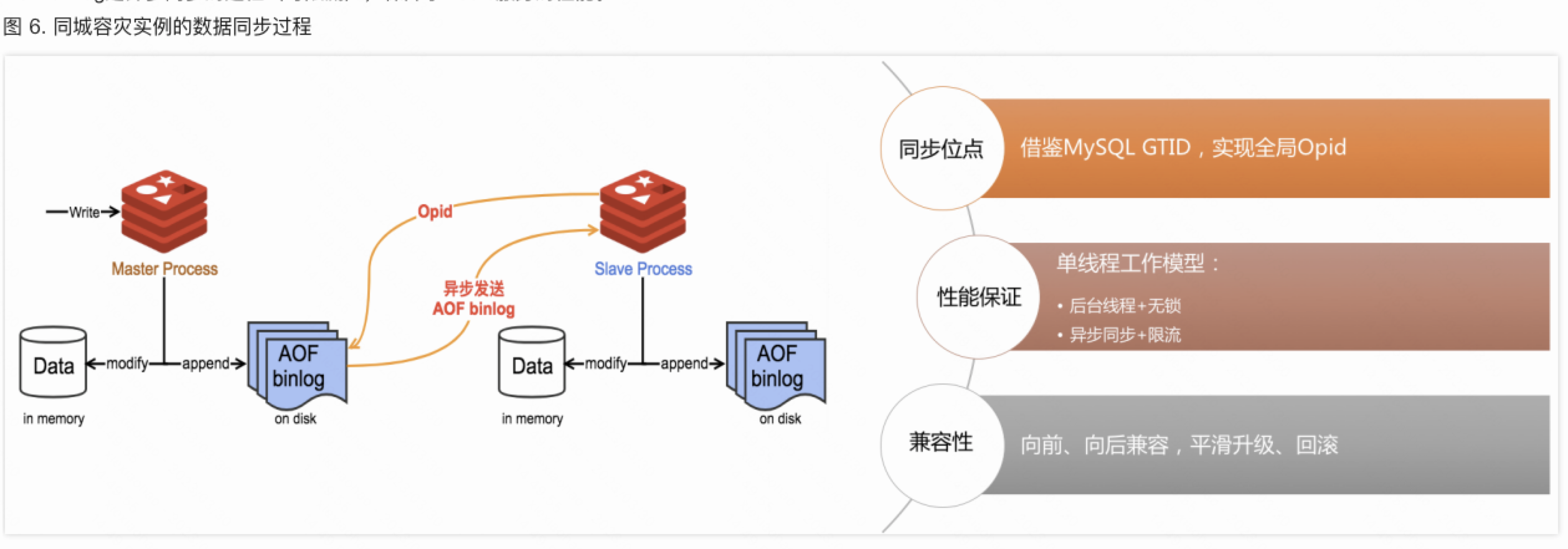 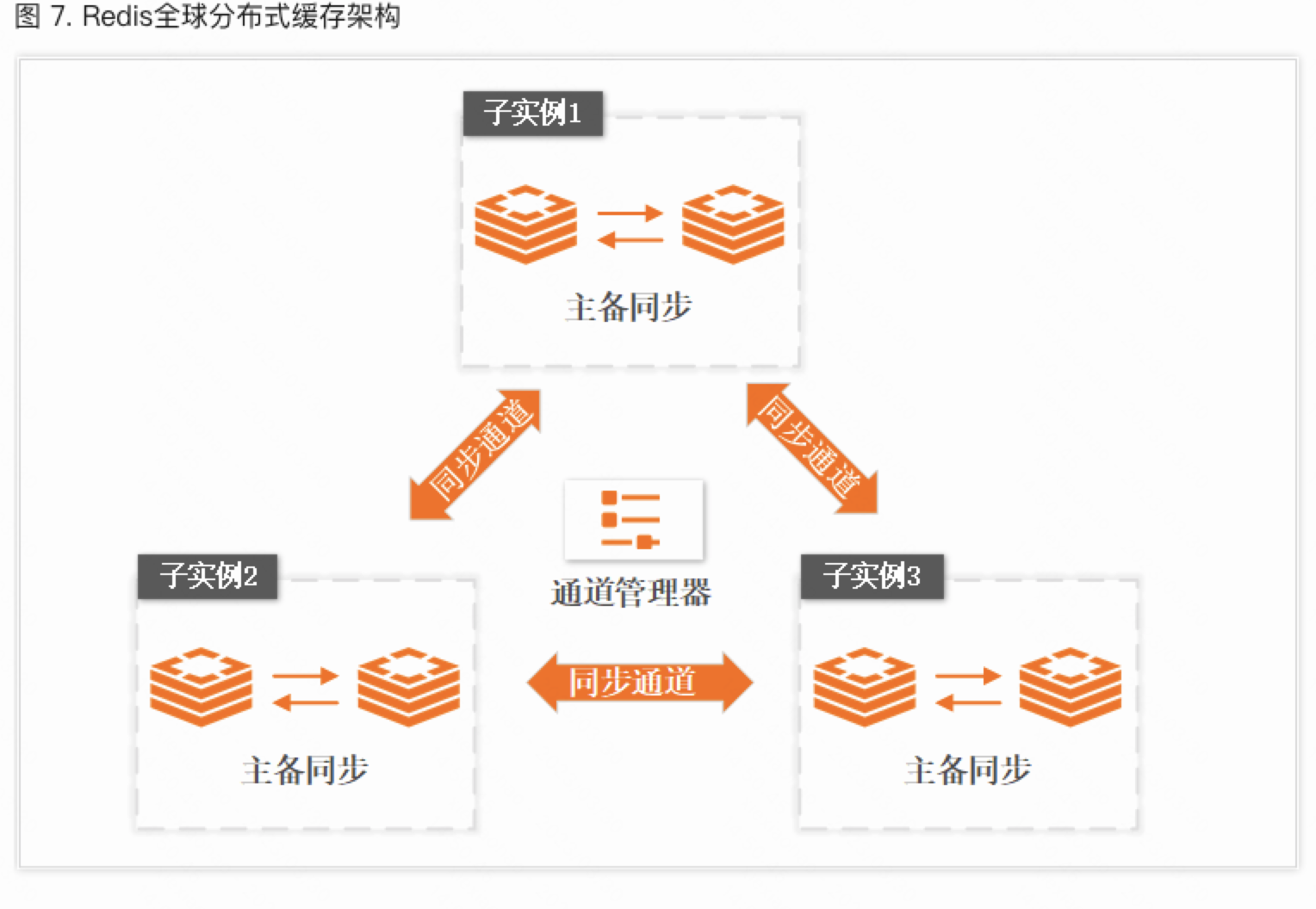 |
多可用区实例具有更高的可用性和容灾能力。主机、机架、可用区级容灾能力。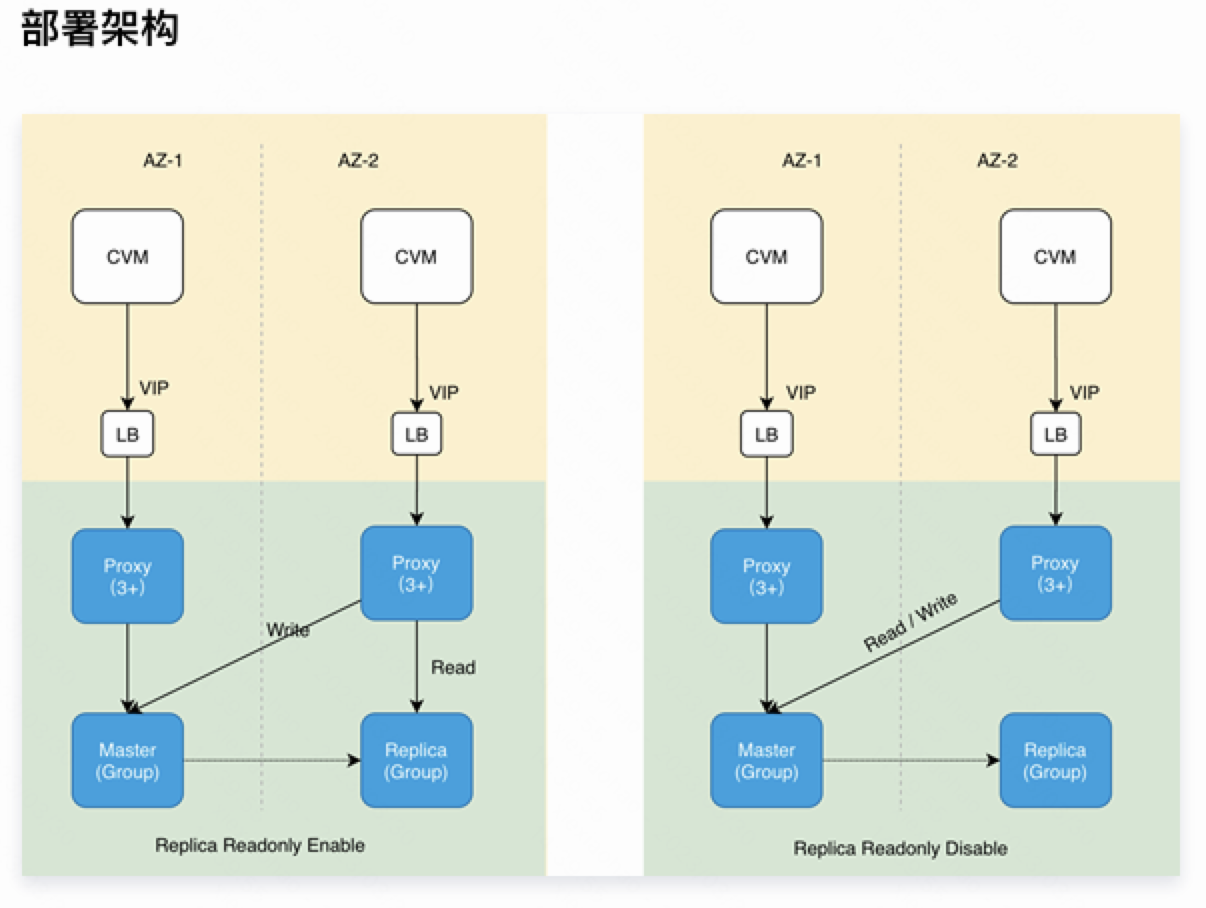 两可用区部署: 两可用区部署: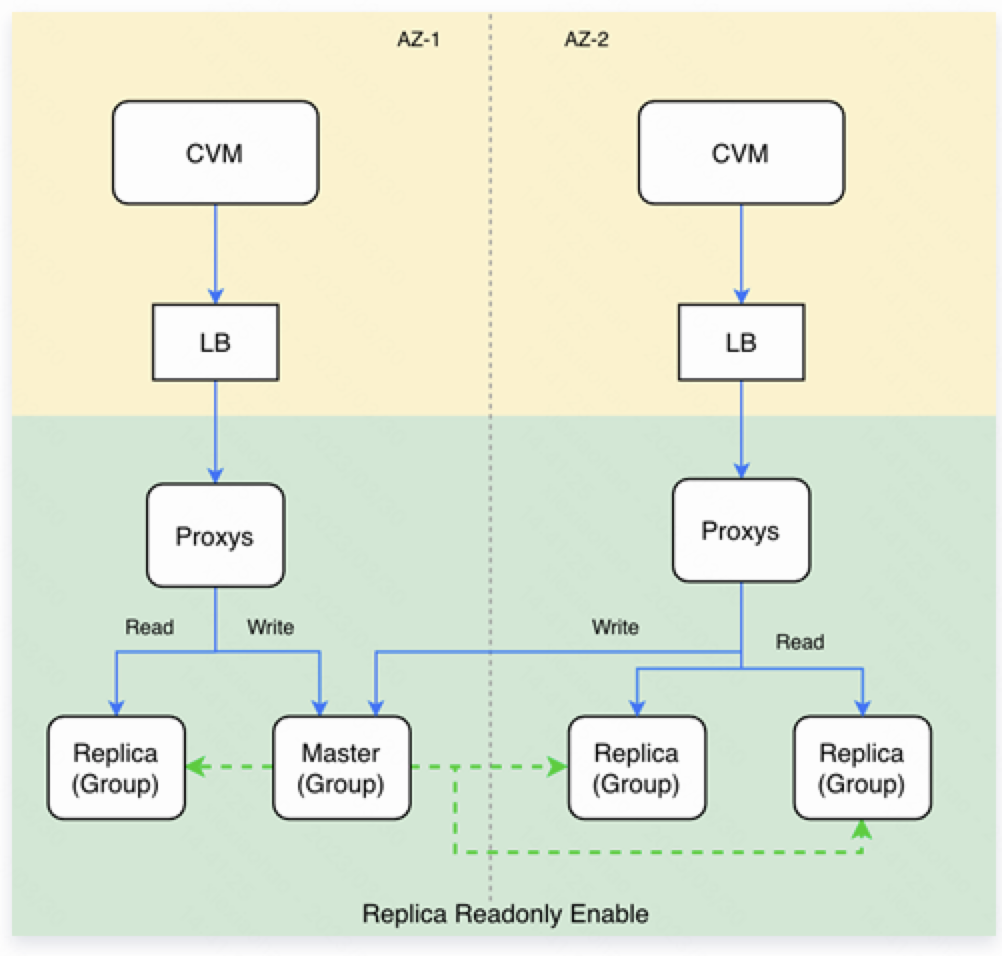 |
方案
针对目前redis容灾问题,整理几个方案思路,供参考讨论,具体可行性及成本待进一步调研验证
- AZ故障时,Gitlab reids容灾接受短时间的redis双写问题,尽量减少故障恢复处理时长(具体方案待补充)
- 改造Gitlab,支持redis cluster模式?
- 如果使用redis cluster模式,就要确保mutli-key都在同一个slot,否则会出现错误:ERR CROSSSLOT Keys in request don’t hash to the same slot,而Gitlab源码中redis使用了多multi-key的命令场景,如Gitlab::Redis::Cache.with { |redis| redis.mget(‘foo’, ‘bar’) }
- 搭建Proxy 代理,Gitlab直连proxy,不关注后端redis,proxy能够自动检测redis可用性,并自动摘除/切换redis?
- 使用第三方云服务商,调研公司云集CMP
改造成本,维护成本,潜在风险等多方面考虑。
2023.7.10更新
上次讨论遗留问题:
- 分析数据可不可以丢失,丢失成本?
- 缓存类数据可容忍丢失,如仓库数据、session等,
- sidekiq队列任务不可容忍丢失,如merge更新合并、webhook等丢失后可能影响代码错乱、丢失等风险
- 分析使用cluster模式的命令,有哪些不支持,影响有哪些? 我们是否使用? 是否可以部分切换cluster模式
- 分两类,一类是multi-key命令,如mget,缓存类使用,通过hash tag方式改造,有可能使用cluster模式,如redis-ratelimiting
- 另一类阻塞类命令,sidekiq使用brpop,属于cluster模式受限制命令,无法使用cluster模式
- 分析故障恢复后,双redis数据不一致的影响?
- 相比数据丢失,数据不一致可能影响更大、更麻烦。
- redis同学确认主和冷备切换同步逻辑,故障时是否停止同步任务,同步方向
- redis AZ故障前,热备1向冷备2同步,AZ故障时,同步会断开,需要业务切换redis连接到冷备2,此时原热备1相当于没有流量和数据。业务切换完成后,需要找redis同学重新开启同步,即冷备2(新的热备)向热备1(新的冷备)全量同步。
- 若故障恢复后,原热备1还有流量,此时会双集群读写,可能会数据不一致,公司redis无法处理解决这种情况
- 服务注册、服务发现的思路,Gitlab应该连哪个健康的节点,问题节点自动摘除、切换
- rails健康检查(curl http://localhost/-/readiness?all=1),定时任务,检测redis是否健康,PING-PONG ,若不正常,则修改redis连接配置,并重启reconfigure
- sidekiq健康检查,redis健康检查(目前不能)
- 最好集成Gitlab,包含redis连接信息,或者新增API实现 redis health check,或者脚本实现,附带Gitlab连接redis信息,二者需保持一致
1 | |
Gitlab redis详细调研
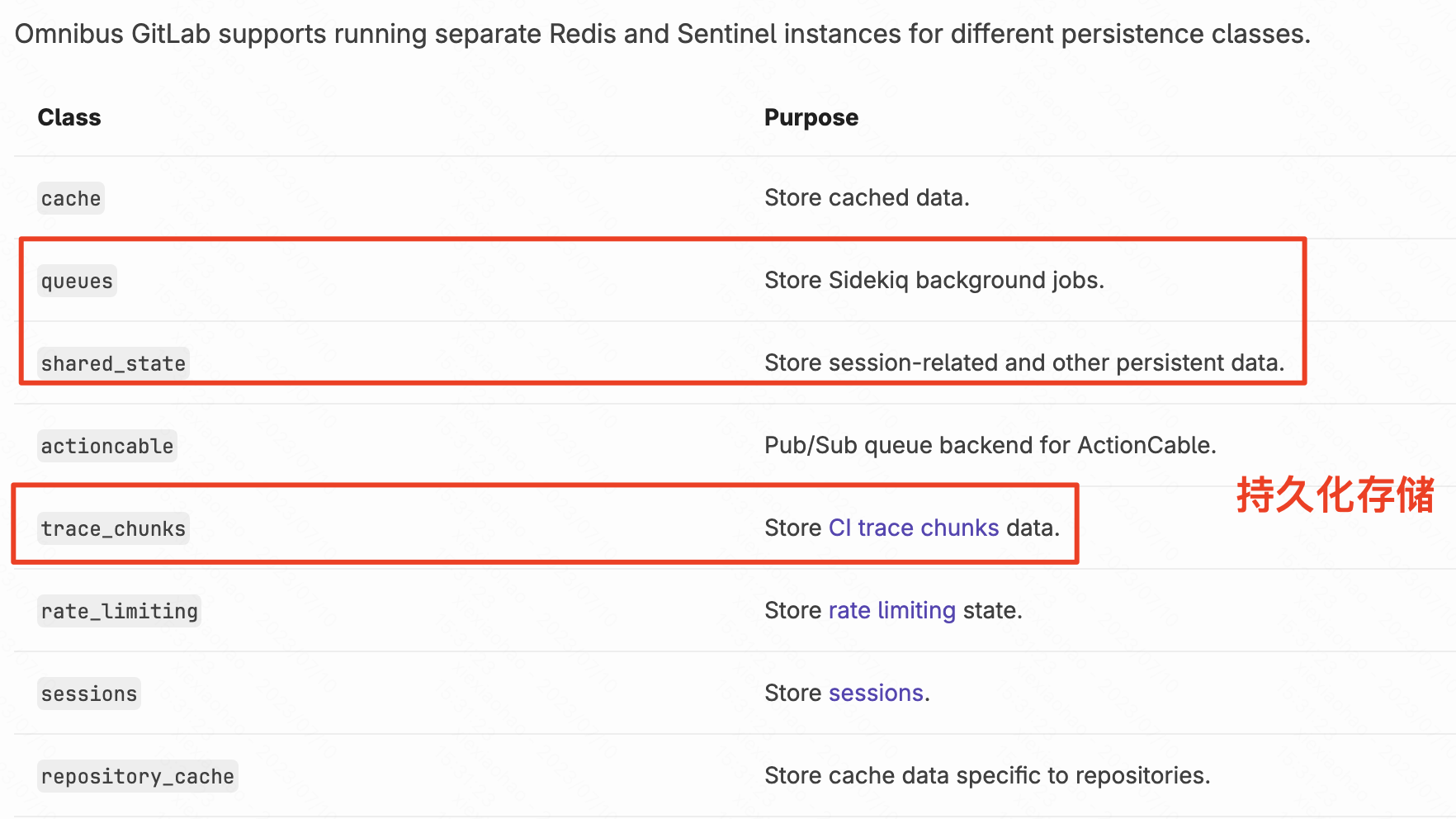
redis分为不同的种类,其中 Redis queues, shared state, and tracechunks是需要持久化存储的,目前都是同一个reids集群存储。
| redis集群 | 存储数据内容 | 补充 |
|---|---|---|
| gitlabHARedisSentinelNew | queue队列 1%session 30%shard_statetrace_chunks**rate_limiting(可容忍丢失)**之前拆分集群历史遗留数据(不过期)52%其他 15% | 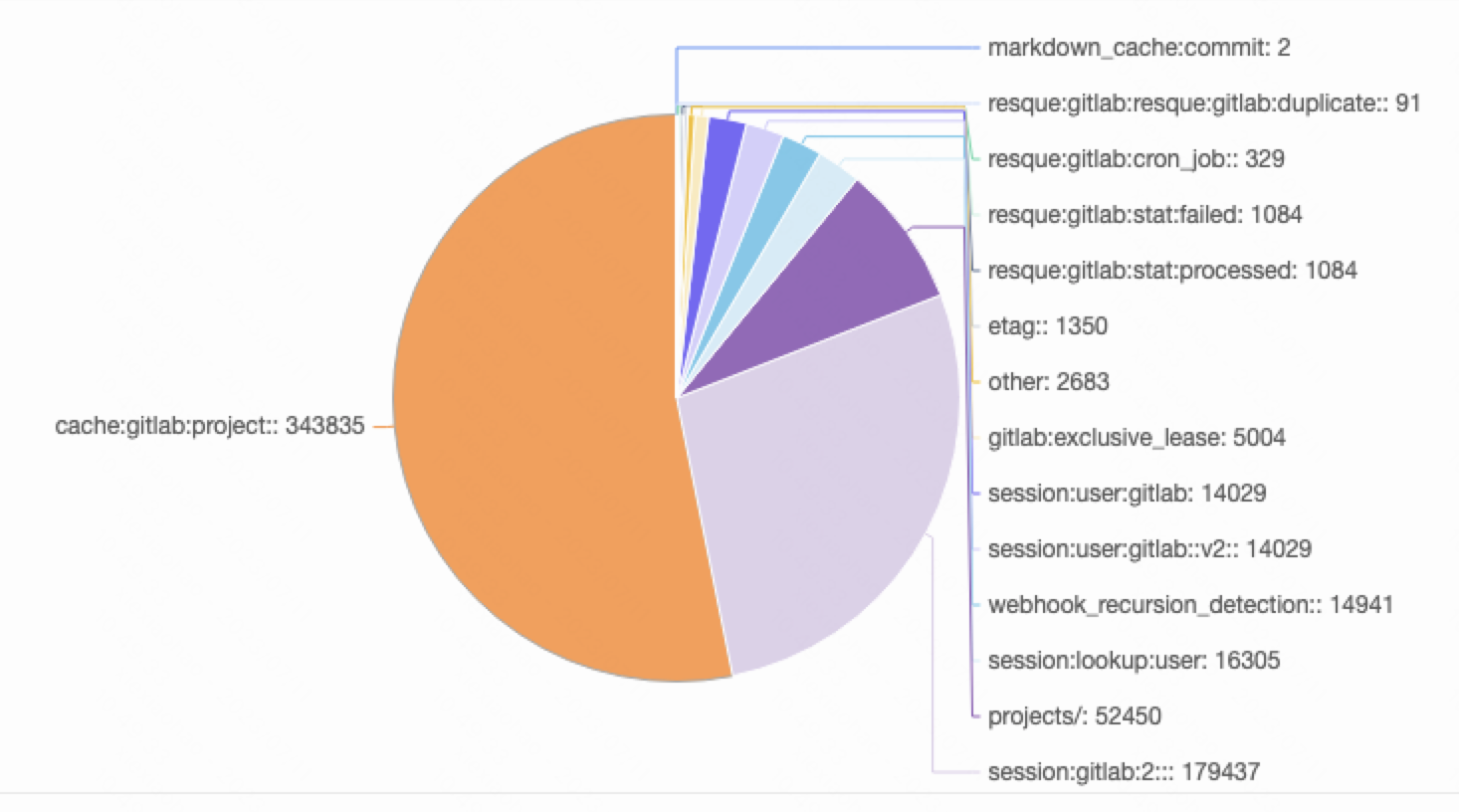 |
| gitlabRedisCache | 缓存cache,可容忍数据丢失。新旧集群双写,无需数据同步迁移存在不过期的数据?49737个 | 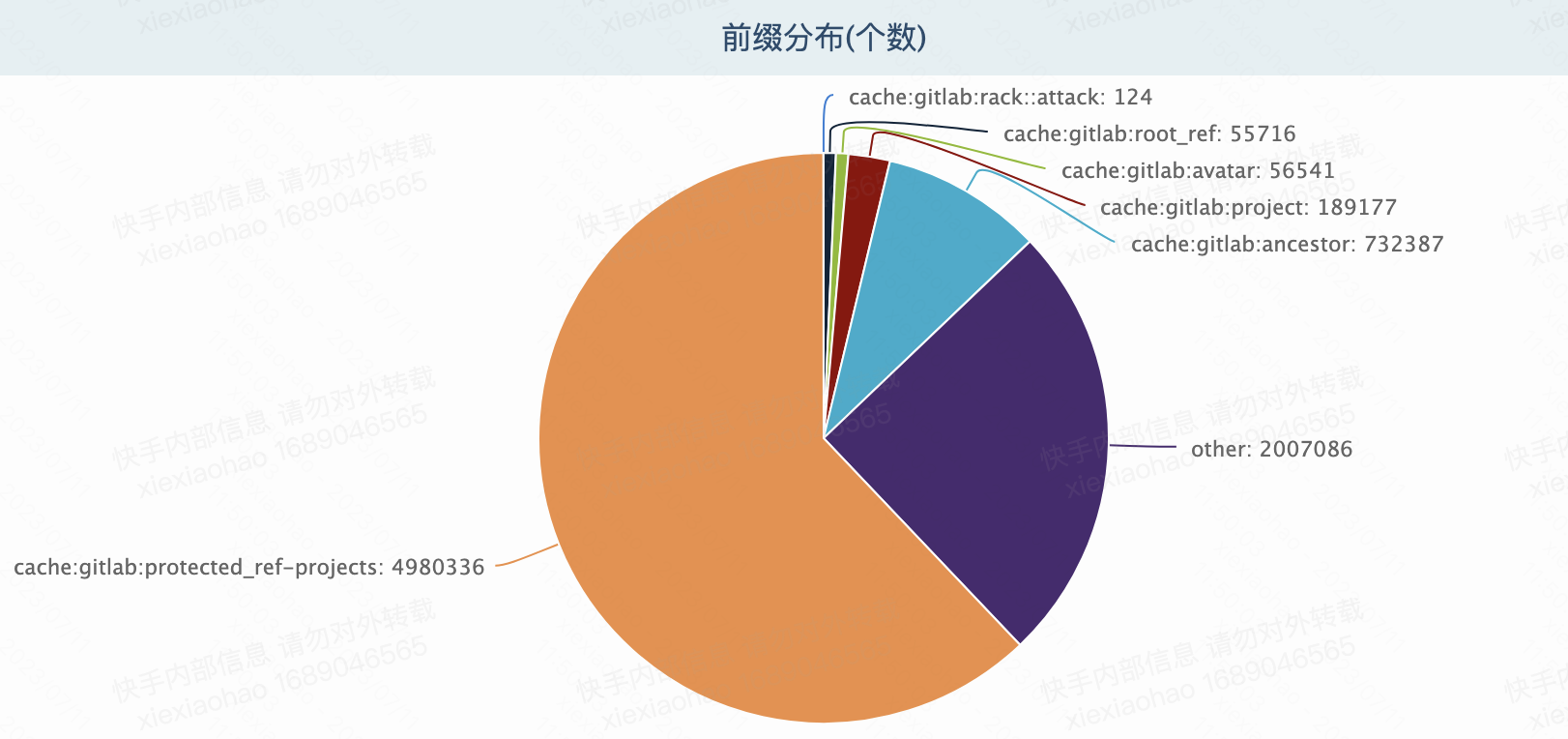 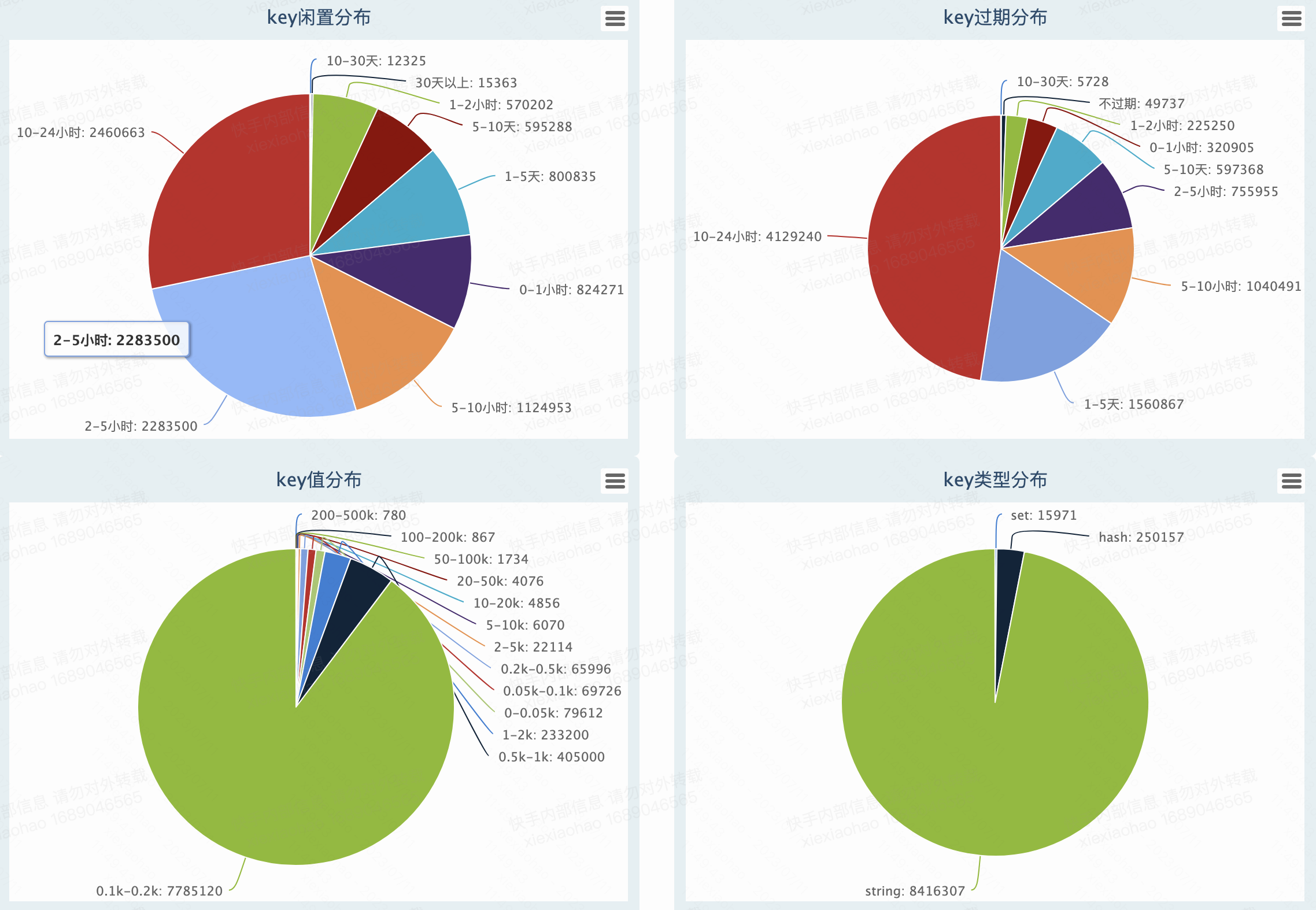 |
Gitlab社区相关issue讨论redis水平扩展性,Redis cluster vs redis::Distributed, 其中redis cluster模式,sidekiq是个例外,不能使用。sidekiq中使用的大量的redis brpop命令,属于cluster模式受限命令
https://gitlab.com/gitlab-com/gl-infra/scalability/-/issues/1986
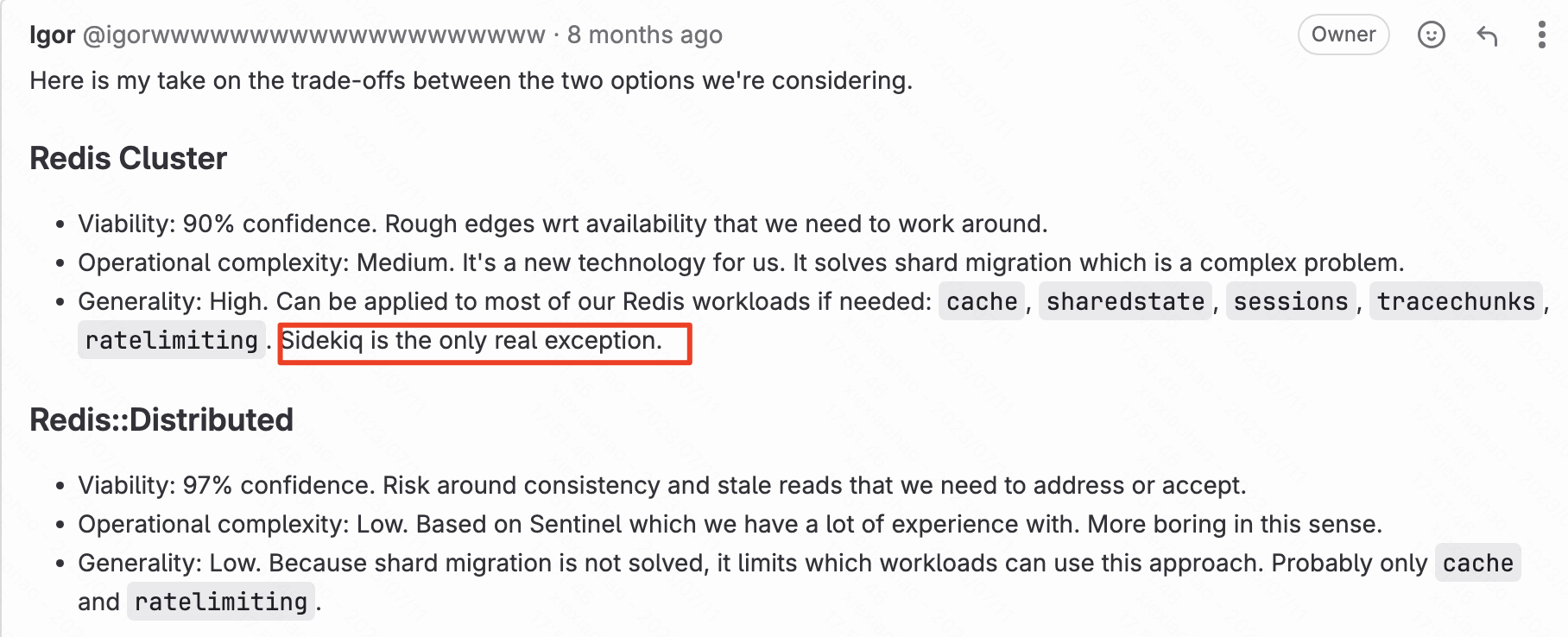
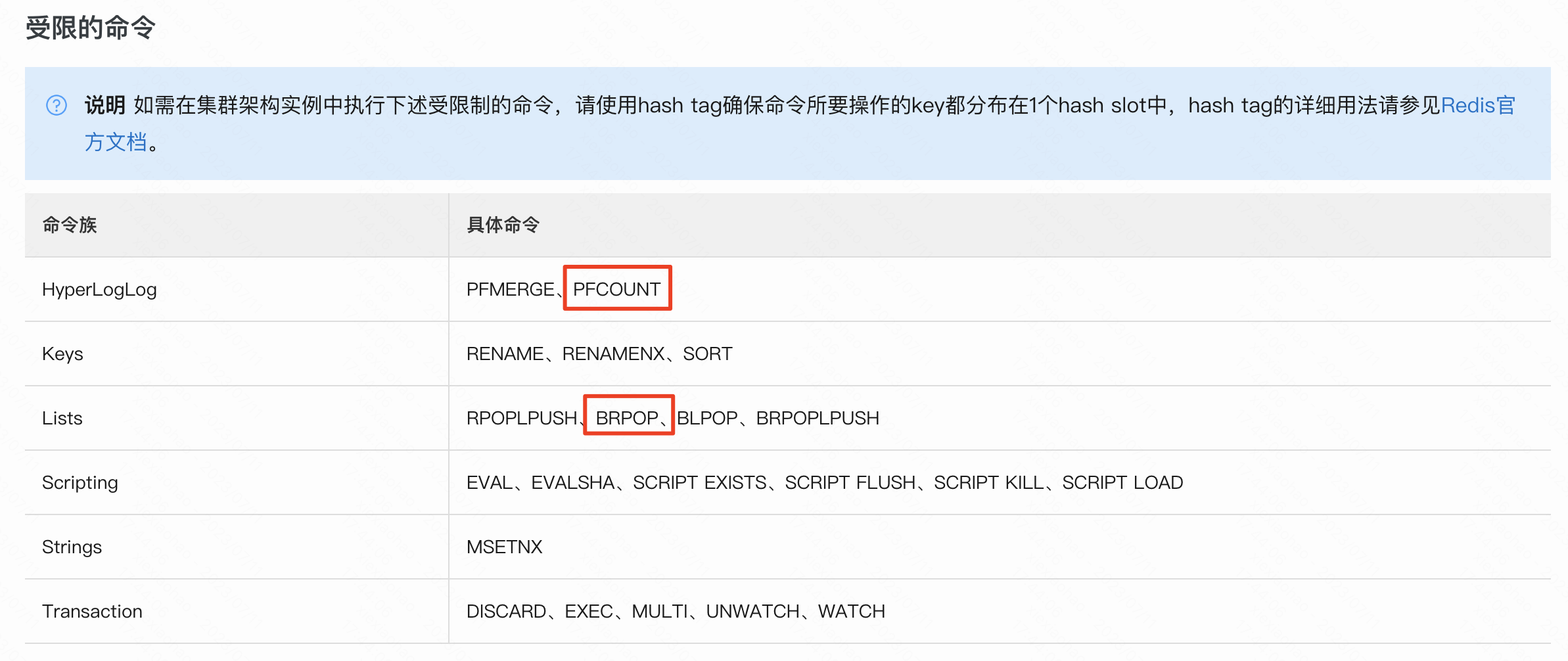
redis cluster模式命令限制
sidekiq异步队列
Sidekiq 是 Ruby on Rails 应用程序中使用的多线程后台作业处理系统。Gitlab中主要执行包括:推送后更新合并请求、 发送电子邮件、 更新用户授权、 处理 CI 构建和管道等。目前总共大概350+种队列任务
Gitlab社区新版本支持redis cluster模式探索
目前Gitlab redis cpu和内存使用限制,不支持横向扩展。
Gitlab后续新版本探索和支持redis cluster,v16.0版本支持rate limiting类型
GitLab supports Redis Cluster only for the Redis rate-limiting type, introduced in epic 823.
rate limiting类型几个考虑:
- 没有分片命令操作(has no cross-slot operations)
- 数据丢失可容忍度高
- 数据生命周期都是短暂的,不用迁移现有数据,直接切换使用新的集群,相对成本较低
- 从Omnibus拆分单独的redis管理配置
- redis版本7, 包含一些专门针对 Redis Cluster 的修复和改进
Gitlab社区目标是redis-cache类型迁移使用redis cluster模式,里程碑2023-7-28
2023-7-19 三次更新
TODO:
gitlab 切换redis配置自动化操作,降低人工操作错误率和时间成本
redis单个集群跨机房,风险点调研确认,决策是否自建redis sentinel跨机房集群
- redis主从复制严重依赖网络,虽然redis不断提升复制能力(Redis 主从复制的原理及演进),sync->psync->psync2,但redis部署在不同的IDC,发生长网络抖动时,可能会出现全量复制风暴,全量复制风暴对可用性是毁灭性的
- 网络延时影响:主从复制,proxy访问转发,sentinel探活,这些事情都是要求时效性要求较高的,比如说出现网络抖动,同机房可能就是抖一下,跨机房可能延迟超过探活直接切换了
- 全量同步fork 耗时过长,阻塞主进程,执行fork 时,需要拷贝大量的内存页表,这是一个耗时较多的操作,尤其当内存使用量较大的时候。fork 的时候主进程阻塞 100 多毫秒,这对 Redis 而言,实在太长了。另外fork 之后,如果主库中有不少的写入,那么由于写时复制机制,会额外消耗不少的内存,还会增大响应时间。

小结:kcc不支持单redis集群跨IDC机房部署。也不建议自建redis sentinel跨机房集群
- 双集群热备-冷备模式,单集群故障了,目标是能够实现全自动感知与切换,确保无人值守时服务正常(consul服务发现?)
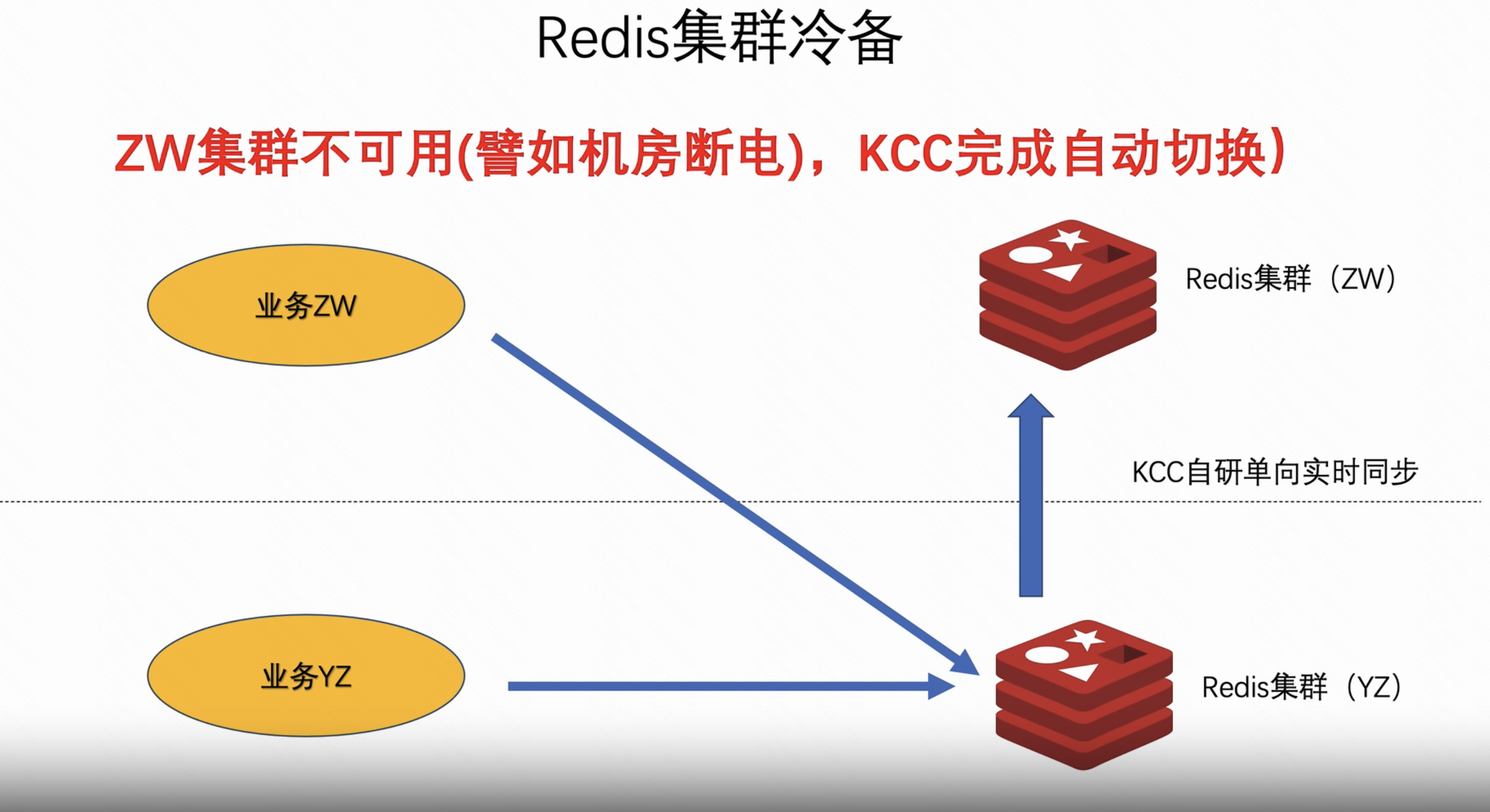
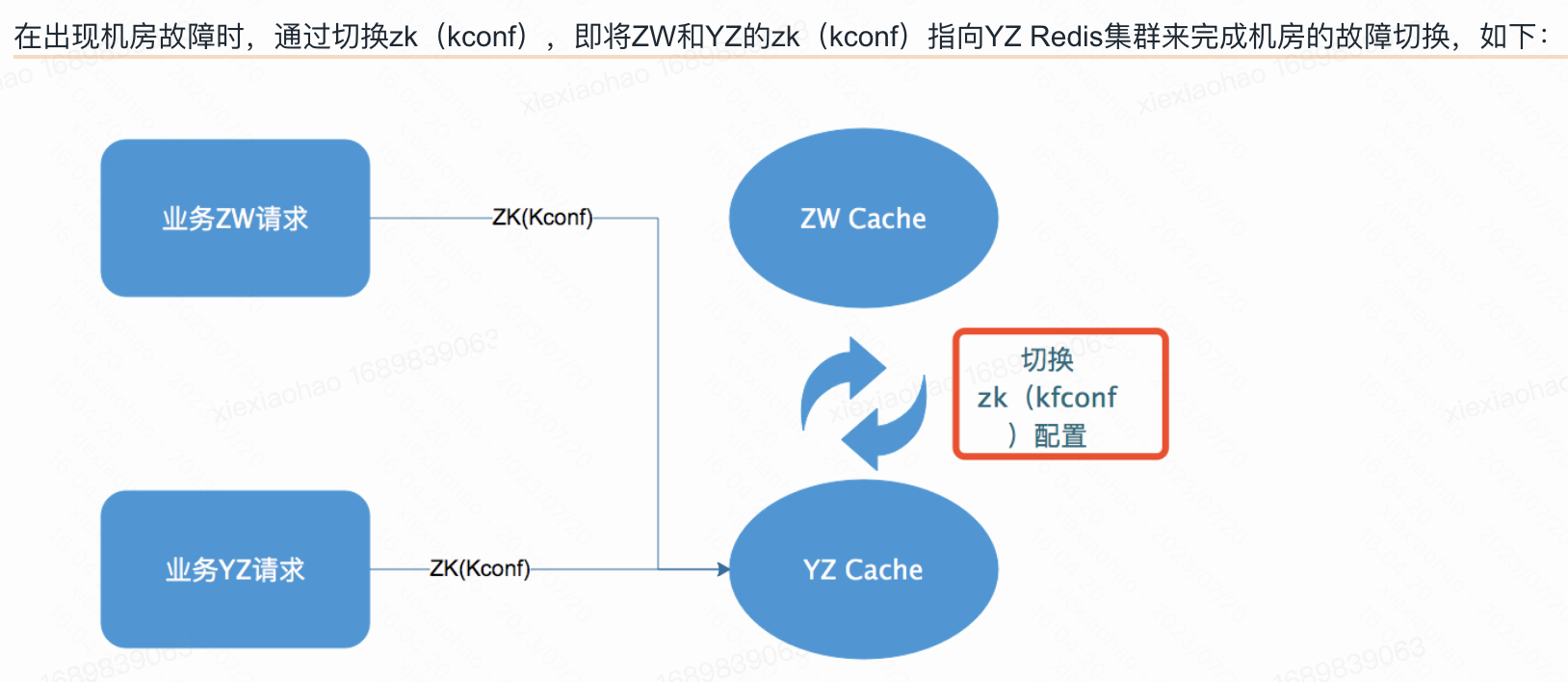
公司kcc redis冷备故障切换示意图: