流量录制回放介绍
1.什么是流量录制回放
流量录制回放是一种自动化测试手段:将生产环境流量录制下来在测试环境回放
流量: 接口入出参,以及内部中间件调用的入出参
1.1 传统测试手段面临的问题
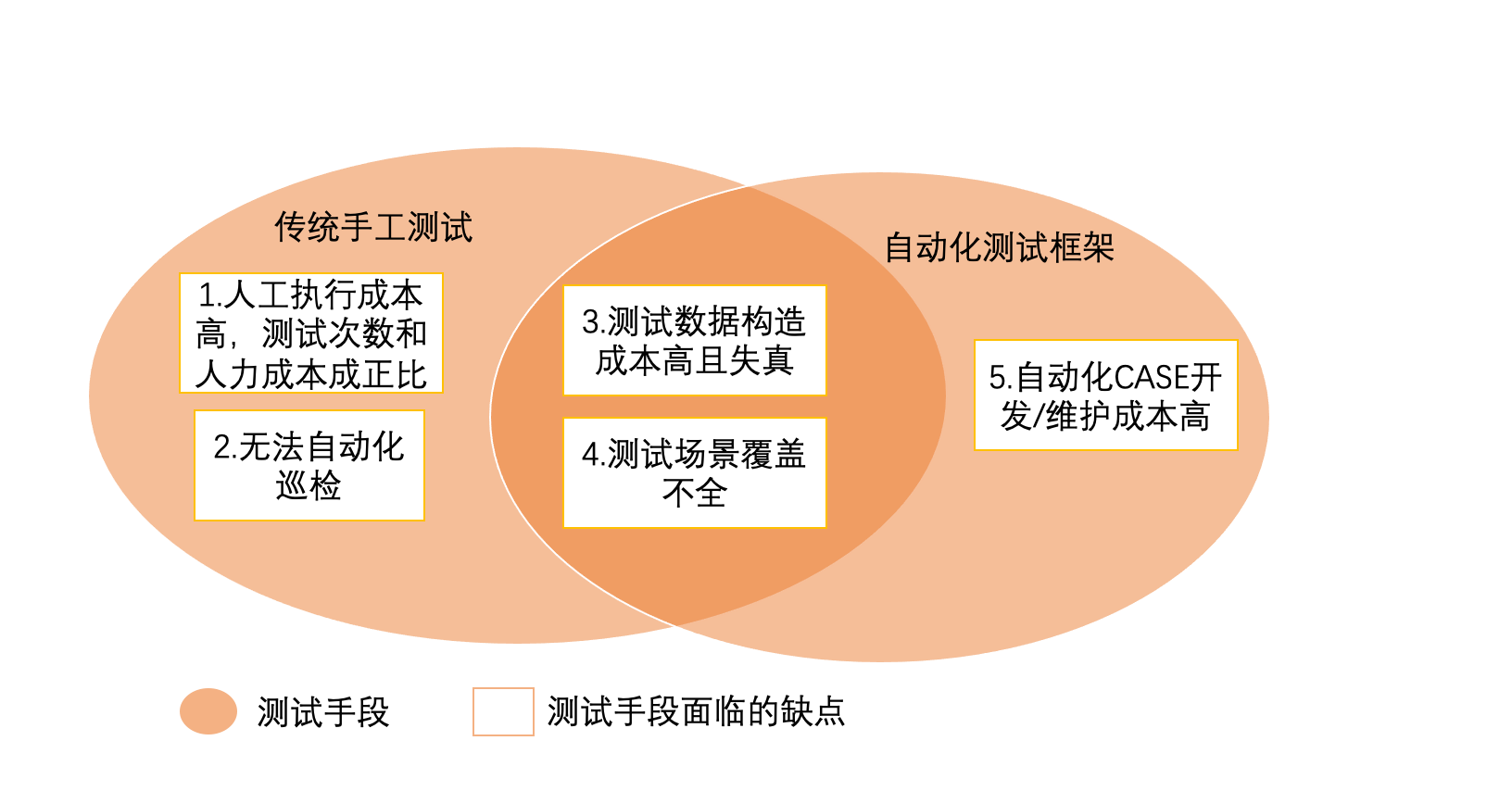
1.2 流量录制回放工作过程
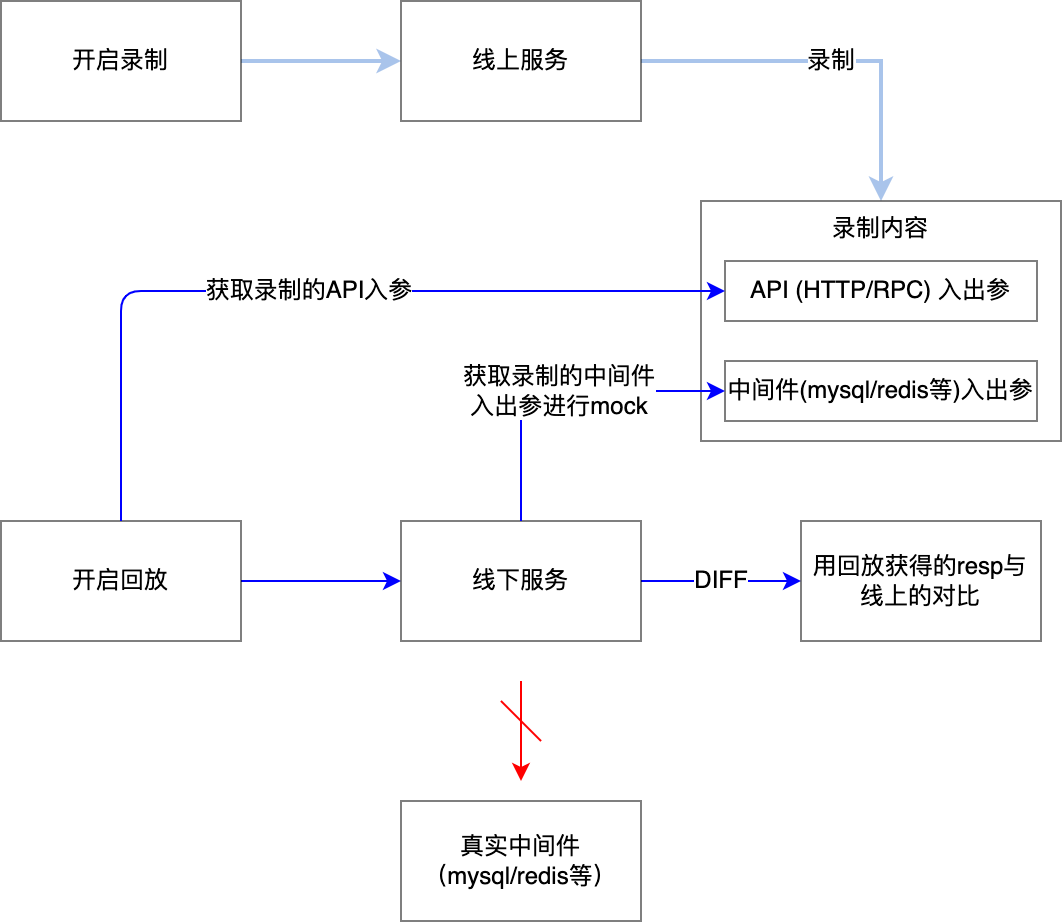
特点:
- 线上真实数据
- 数据量大,覆盖足够多场景
- 自动化录制回放,人工成本低
- 适合批量、巡检
- 一次录制多次使用
1.3 什么场景适合使用流量回放
- 客户端协议不变,服务端重构: 例如海外的双AZ\Trinity项目
- 确认不确定:代码变更后, 预期是对其它接口无影响, 但是又不能完全肯定,而手工测试这些接口成本又太高
- 测试场景覆盖不全:无法构造线上case
- 快速回归测试:可以是上线前的回归测试, 也可以是测试过程中BUG修复后的回归测试
- 自动生成KAT自动化测试用例
1.4 业内成功案例
| 引擎名(所属公司) | 核心技术 | 优点 | 缺点 | 开源 |
|---|---|---|---|---|
| DOOM(阿里) | SpringAOP+字节码插桩 | 业务代码零改造可以录制/mock任意方法 | 问题定位困难降级困难, 往往需要重启从风险角度看,难以让所有实例都接入,阿里也是选取少量服务器接入 | 否 |
| 回声墙(蚂蚁) | 微服务框架+SpringAOP | 风险可控,可迅速降级对系统影响小, ms级别在切面中实现, 可以录制bean实例的任意方法 | 无法录制非bean的方法接入系统需要升级改造 | 否 |
| Sandbox Repeater(阿里) | 字节码插桩 | 同DOOM | 同DOON | 是 |
| Bytecopy(字节) | 类tcp copy | 灰度引流测试用于与真实环境交互 | 不支持线下测试不支持下游和中间件的录制 | 否 |
| 好未来/汽车之家/以及其他 | sandbox |
业内优秀案例优点:
- 业务零改造
- 侵入少量机器
我们的建设原则:
- 兼容业内优点
- 同时支持C++ 和 JAVA
- 避免DIFF效率低
2.流量录制回放架构
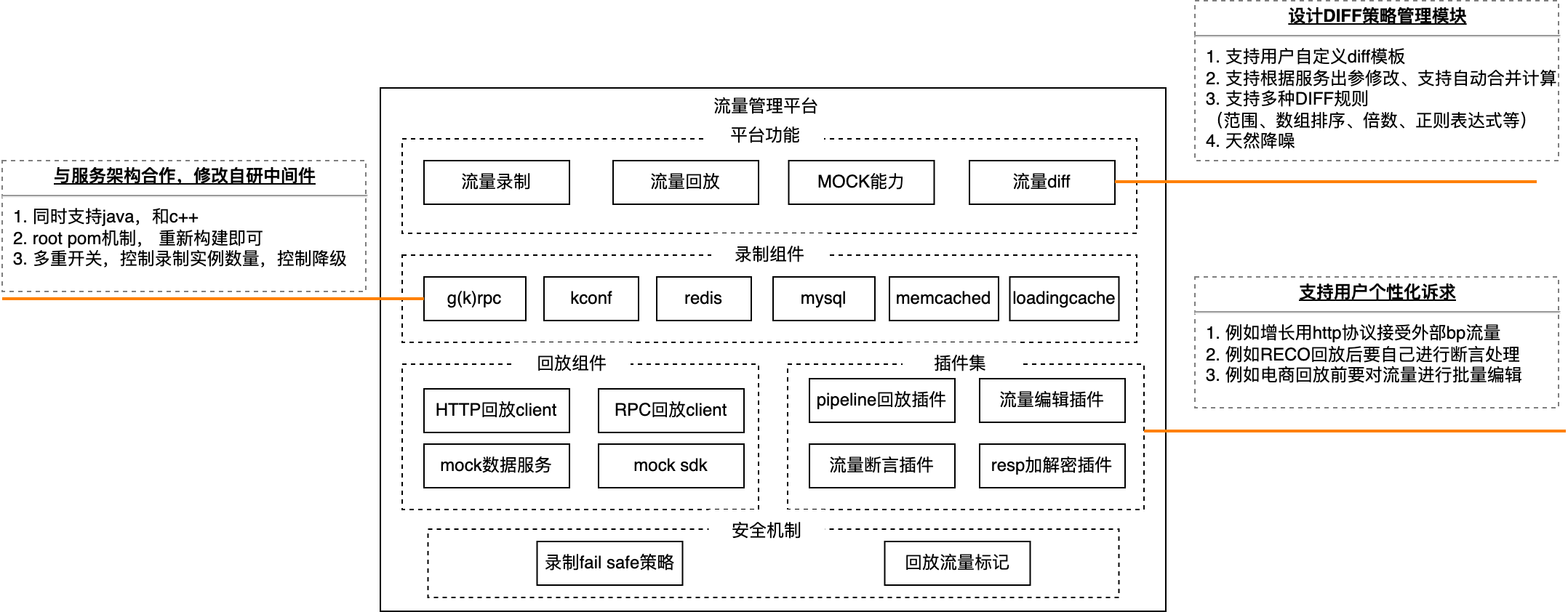
3.主要功能介绍
流量录制回放是一件复杂的事情, 需要用户具备以下能力
- 对被录制服务足够了解,包括服务的读写动作、中间件依赖情况、入出参含义、高/平峰QPS等
- 熟悉KTraffic平台的使用,包括平台各种参数、配置的含义。
- 具备一定的问题排查能力, 了解kbox等常用问题定位手段的应用。
- 简单了解录制、回放工作原理。
因为一次配置多次使用的特点,所以为学习使用方式做出的付出还是值得的。
3.1 流量录制
3.1.1 我们能录制什么
我们支持录制被测服务(即待回放服务)的主流量及其N-1层子流量
被测服务目前支持的包括:
- 使用spring mvc提供的http服务
- 使用ksboot提供的http服务
- 使用java 提供的grpc服务
- 使用c++提供的grpc服务
主流量:即被测服务的入参和出参。
N-1层子流量: 被测服务在其进程内发起的远程调用。 例如被测服务A在其进程内发起了向GRPC服务B的调用, 在A的进程中可以得的B的入参与出参, 此时B的入参出参被称为服务A的N-1层子流量,而在服务B的进程内产生的一切子调用都不会被录制(因为服务B没有打开录制配置,甚至根本就没有集成录制组件)。目前JAVA服务支持录制的子流量类型包括:
- G/KRPC
- mysql
- redis
- memcached
- kconf
- loadingcached
- kafka producer
- rocketmq
- keycenter
- idseq
- kswitch
即被测服务A发起以上7种中间件的子调用时, 其流量都可以被录制。
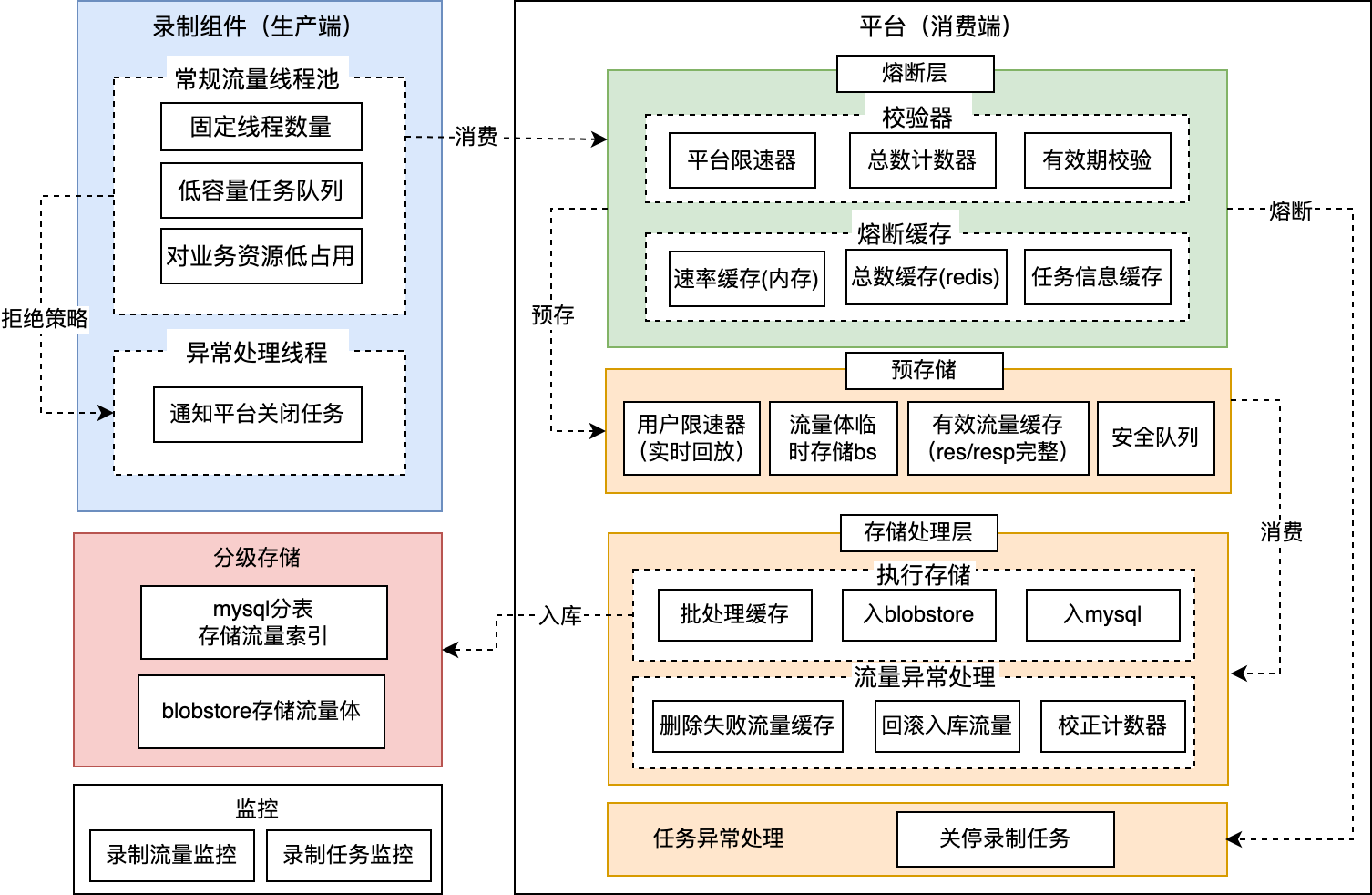
3.1.2 流量录制原理
录制流程
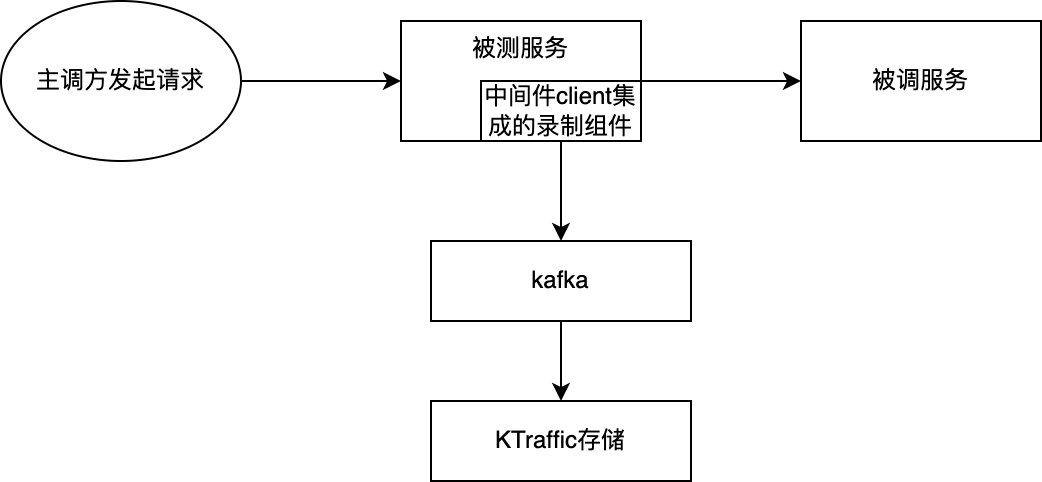
- 中间件client 包括:g/krpc 、mysql、kconf等7种常用中间件的client
- HTTP的录制是通过集成具备录制功能的filter进行。
录制关键架构
3.1.3 使用方如何集成流量录制组件
- g/krpc、mysql、kconf等KTraffic支持的**(非HTTP**)中间件的client通过root pom集成, 用户无需改造。
- 基于ksboot/springmvc的HTTP服务配置方式见:HTTP服务添加录制依赖
其它说明:
- 目前不支持HTTP类型的子流量的录制
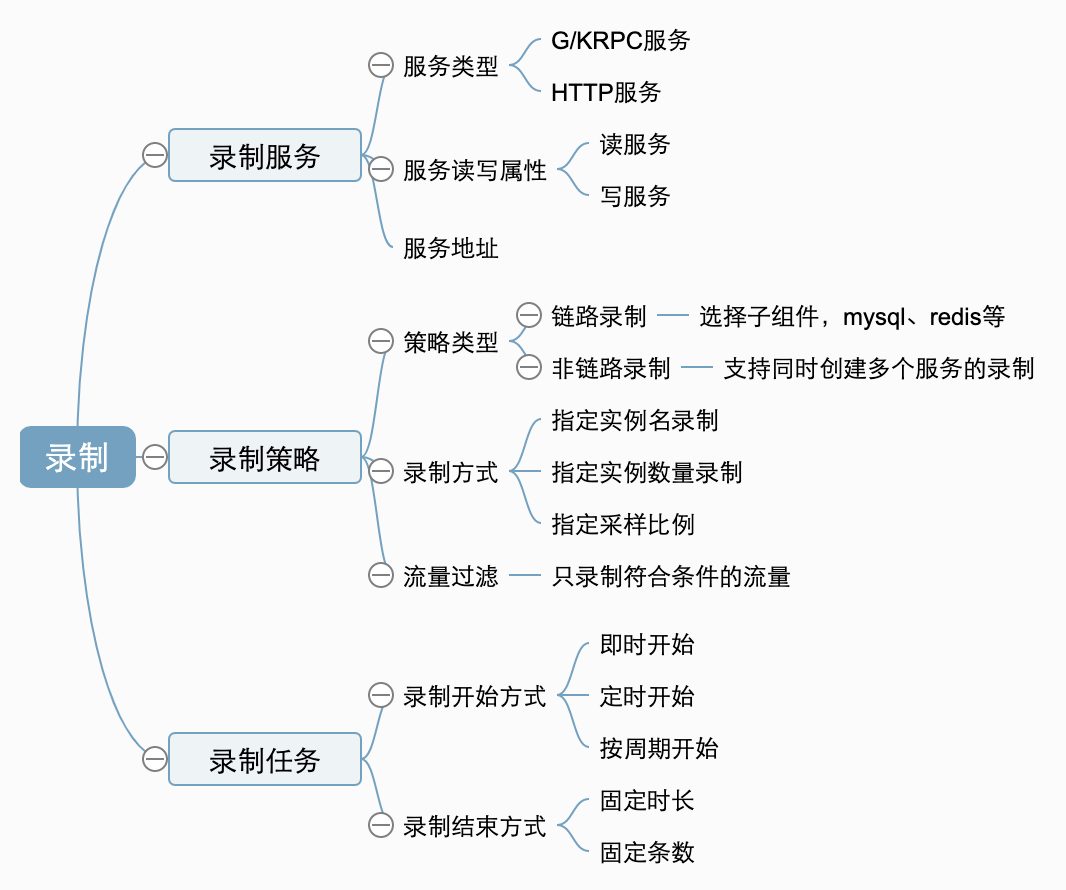
3.1.4 流程与功能
创建录制任务的流程

录制功能介绍
3.2 流量回放
3.2.1 MOCK能力
为什么要有MOCK能力?
在流量回放建设之初,因为没有mock能力,我们仅支持回放与生产环境使用同源数据库的服务。所以只能回放读服务,否则会对线上产生脏数据。因此流量回放能力一般被使用在集成测试阶段, 对线上的服务做最后的回归。

而更多的测试行为发生在staging环境, 为了使线上录制下来的数据能在staging环境回放,我们开发了MOCK能力。
MOCK能力扩大了流量回放的使用场景

MOCK配置能力
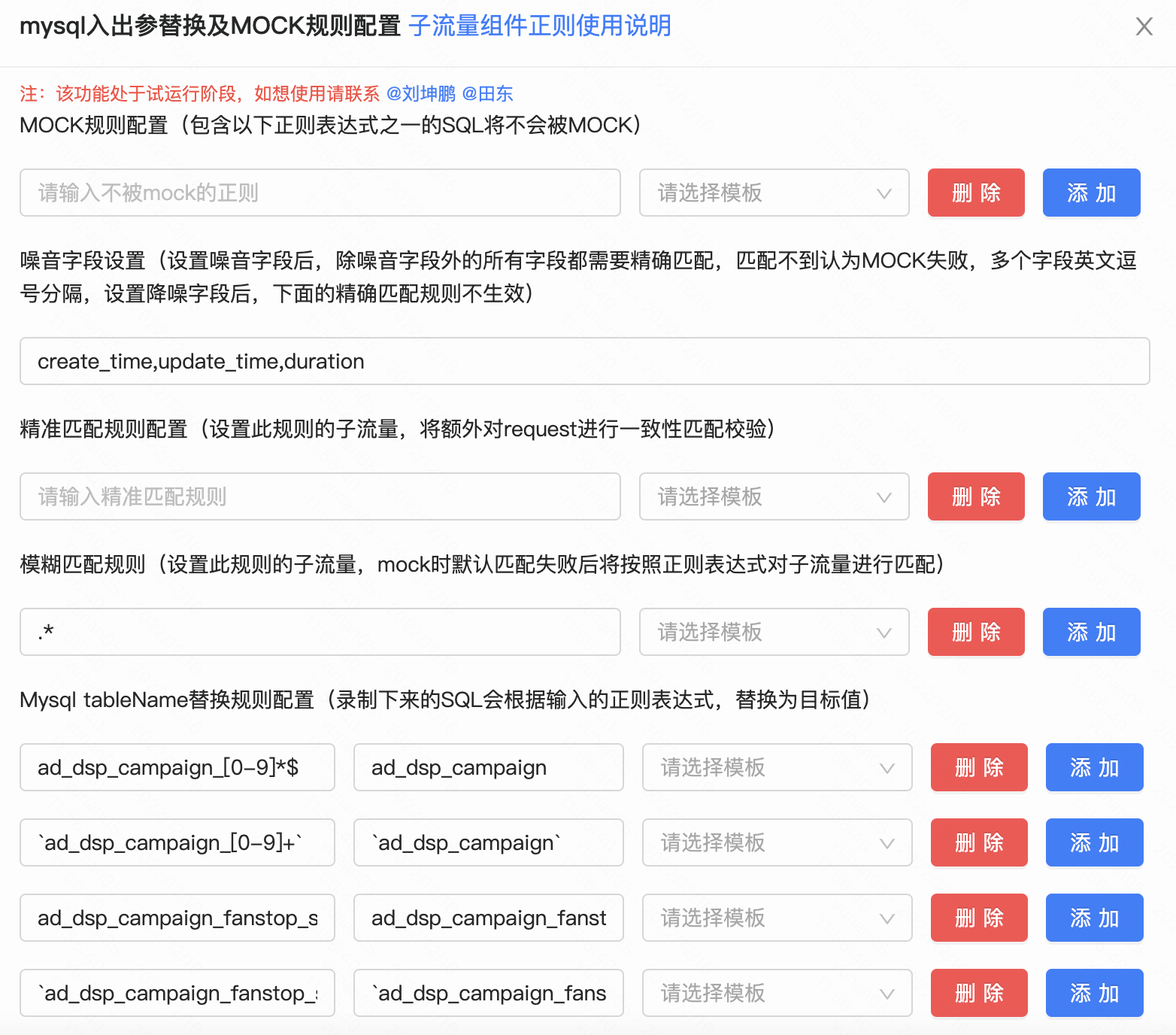
很多情况下, 因为线上线下的环境差异、参数随机性等因素, 即使有了基本的mock能力,线上的数据也不能在线下自如使用。例如以下场景
分库分表场景。线上一般为会分库分表, 线下一般为单表,回放过程中会因为表名不同而无法匹配到MOCK数据。
- redis、memcached也存在类似问题
随机数(噪音)问题。例如时间戳是在调用发起时生成,每次都不同, MOCK时需要忽略。
mock组件范围限定。 只mock选定的几个中间件,其余中间件访问真是服务。
mock数据范围限定。 对于同类组件的mock, 只mock一定范围的数据, 例如mysql, 只mock固定的几张表
降噪范围限定。 只对固定的表降噪
动作MOCK限定。 例如至mock update 和insert的操作, select 选择性放行。
等等
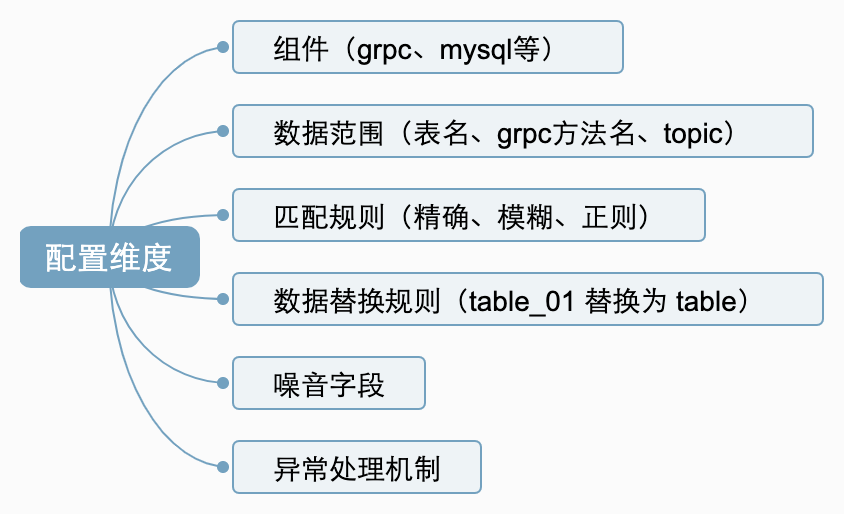
MOCK组件配置示例:
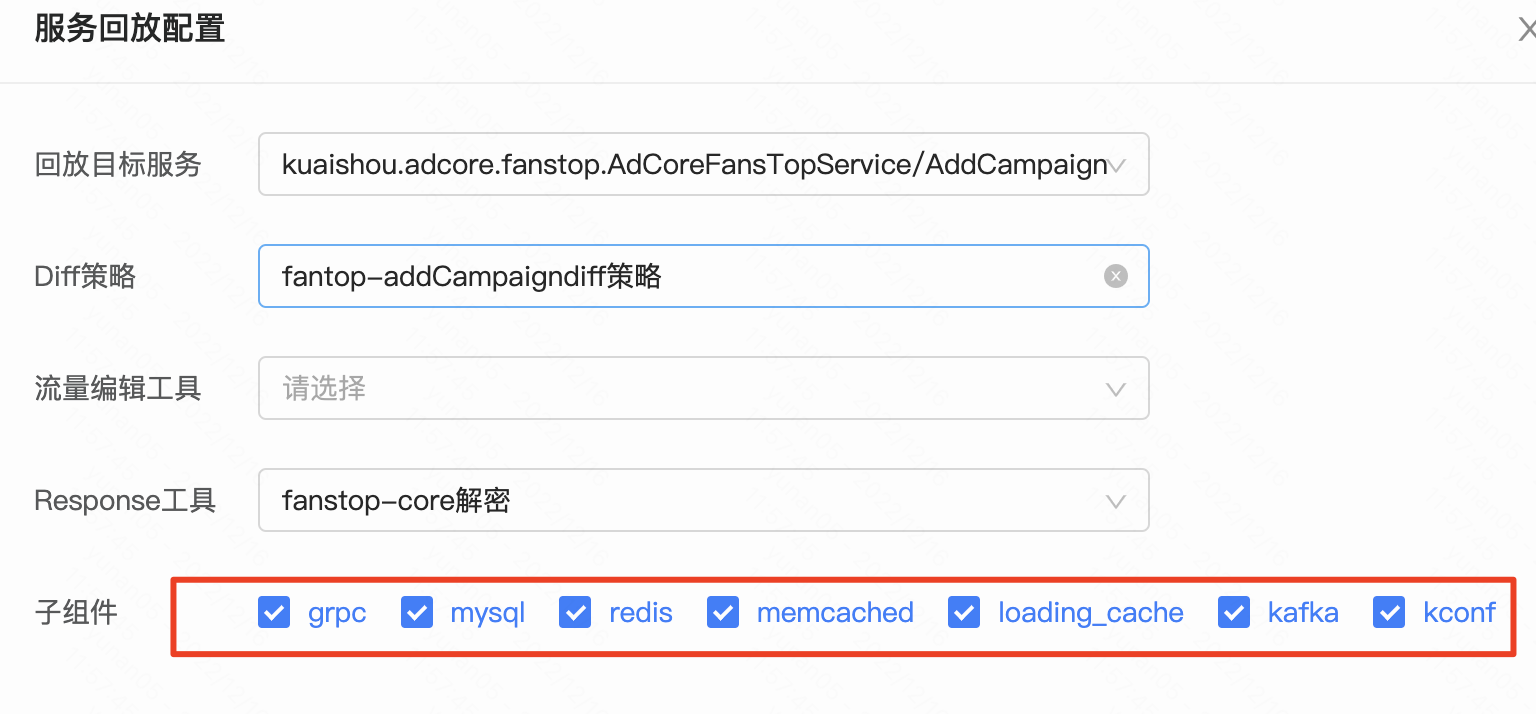
MYSQL MOCK规则配置示例:
3.2.2 回放流程

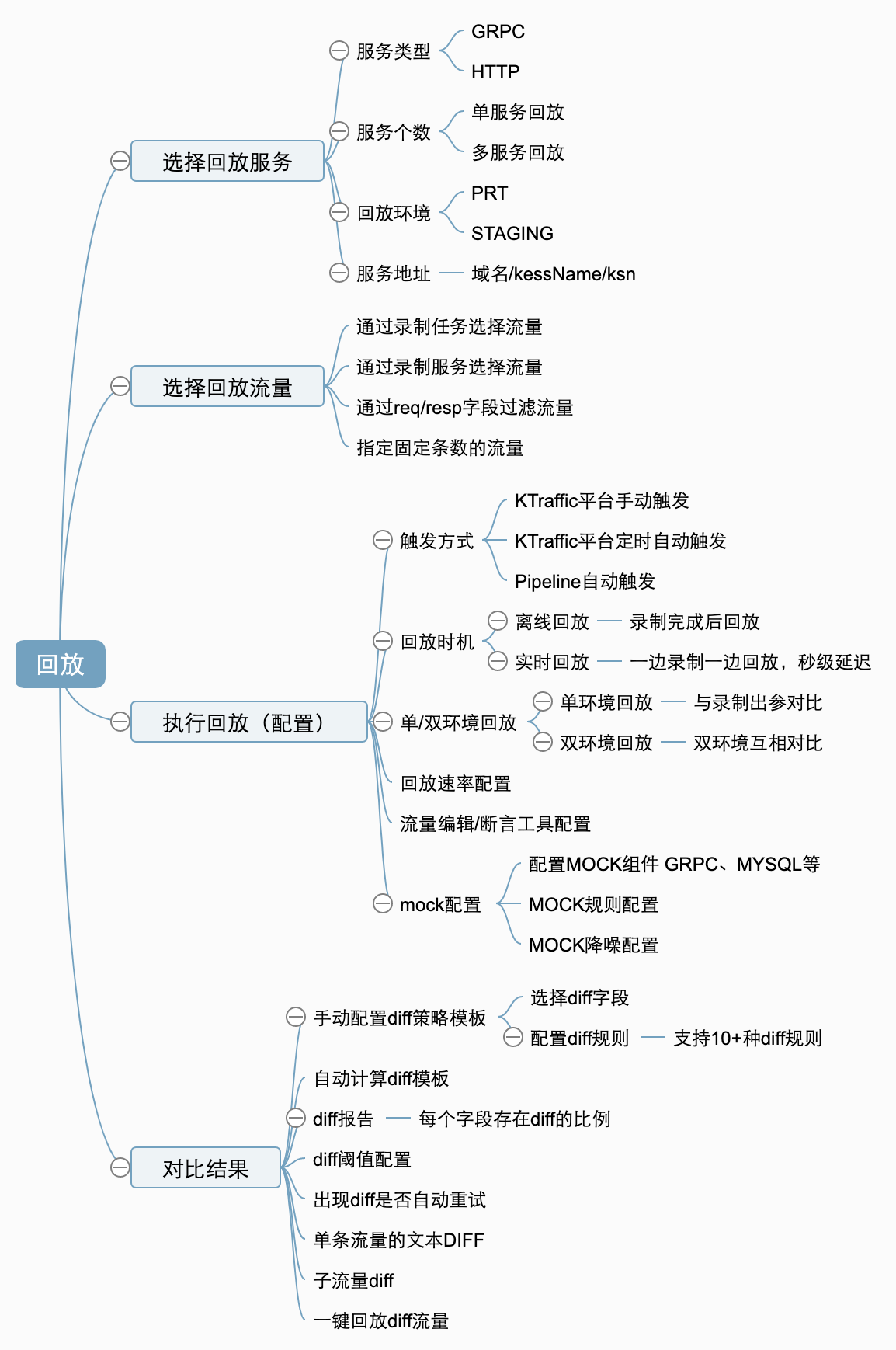
3.2.3 回放功能
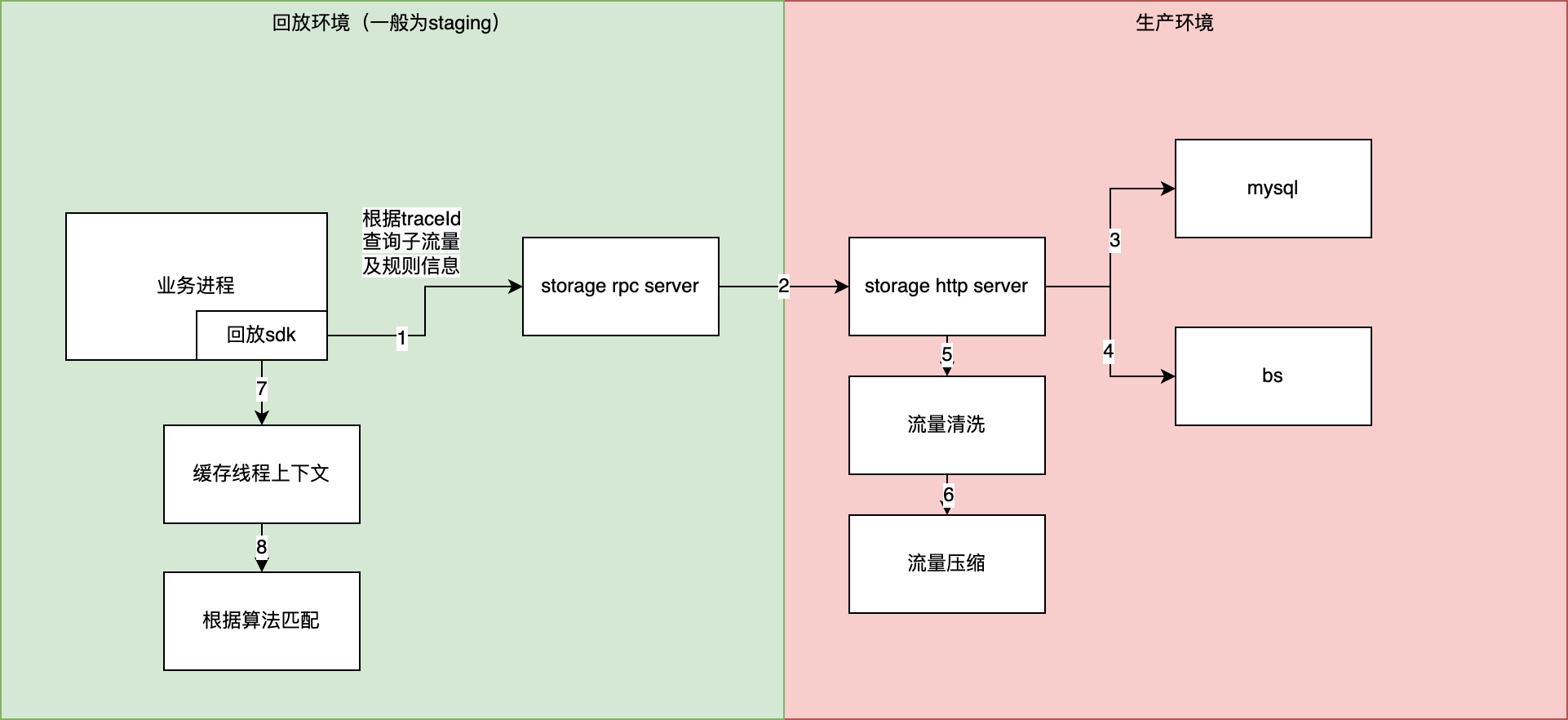
3.2.4 回放执行流程
3.3 流量Diff
流量回放之后,对比返回值是我们发现被测代码是否存在BUG的主要手段, 因此在DIFF返回上,我们开发了大量的功能, 期望能满足各个业务方不同的Diff需求。 常用的主要是以下三种diff能力
- Diff 报告 —— 反映一次回放任务(包含多条流量)整体的Diff情况
- 子流量Diff —— Diff一条流量的在回放过程中的中间状态
- 单条流量文本Diff —— 用于调试diff策略或者排查单条流量的回放情况
3.3.1 Diff报告
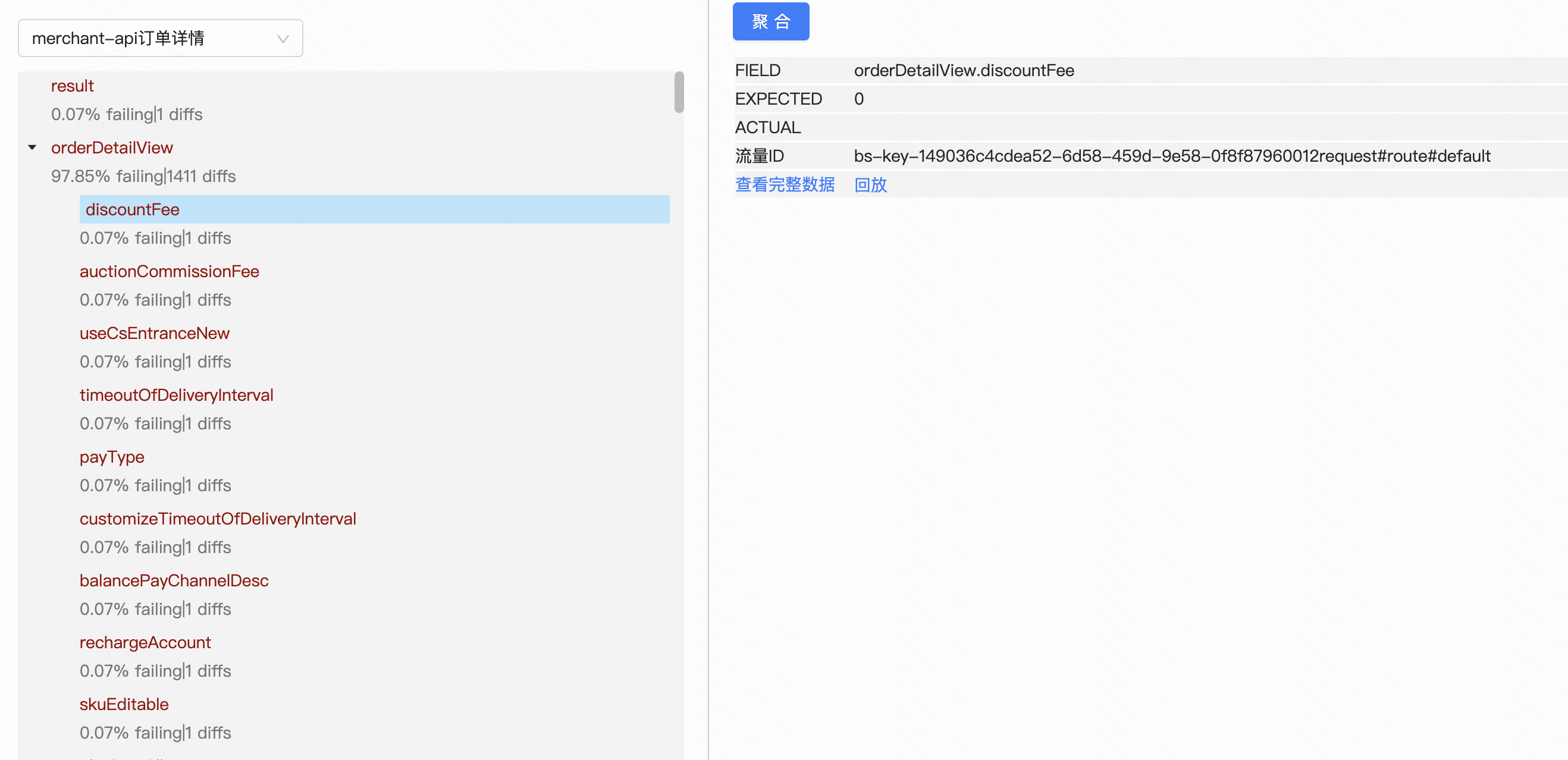
一次回放任务通常会包含多条流量, 甚至会有数万条流量,如果一条一条去看diff结果显然不现实,因此我们参考了twitter的 Diffy,设计了Diff报告。 并且增加了自定义diff策略、diff规则、对象下钻的能力。
什么是diff策略?
一条流量通常会有上百个字段, 其中不乏包含一些噪音字段,例如timestamp、随机数等, 以及一些本次测试不需要diff的字段, 因此,我需要创建个一个diff策略来描述本次流量回放我们要对比哪些字段。
什么是diff规则?
对比一个字段的两个值, 我们通常除了等于这种简单的对比规则之外, 还需要大于小于、范围对比,如果是数组类型,可能还涉及到排序对比。因此我们设计了diff规则,用来支持此类情况,目前我们已经支持了19种diff规则。
为什么要对象下钻?
例如我们对比的内容是一个元素为对象的数组, 如果想排查问题, 我们要先下钻的数组里面去,然后再下钻到每个对象中, 再看具体是哪个基本类型的字段值不同。
下图展示了一个diff报告的形态, 左侧为报告整体, 右侧为每个字段的对比明细
3.3.2 子流量diff
发现一条流量存在diff的时候, 接下来动作应该是排查这条diff为什么会存在, 常规的方法是去看日志、远程debug 或 使用kbox排查。 但如果我们能在KTraffic平台上看到这条流量的每个中间远程访问的入参与线上录制到的入参的差异,就会一定程度上帮助我们快速为问题。
如下图,展示一条流量的所有grpc的中间访问过程,类似的还可以查看mysql、redis等。
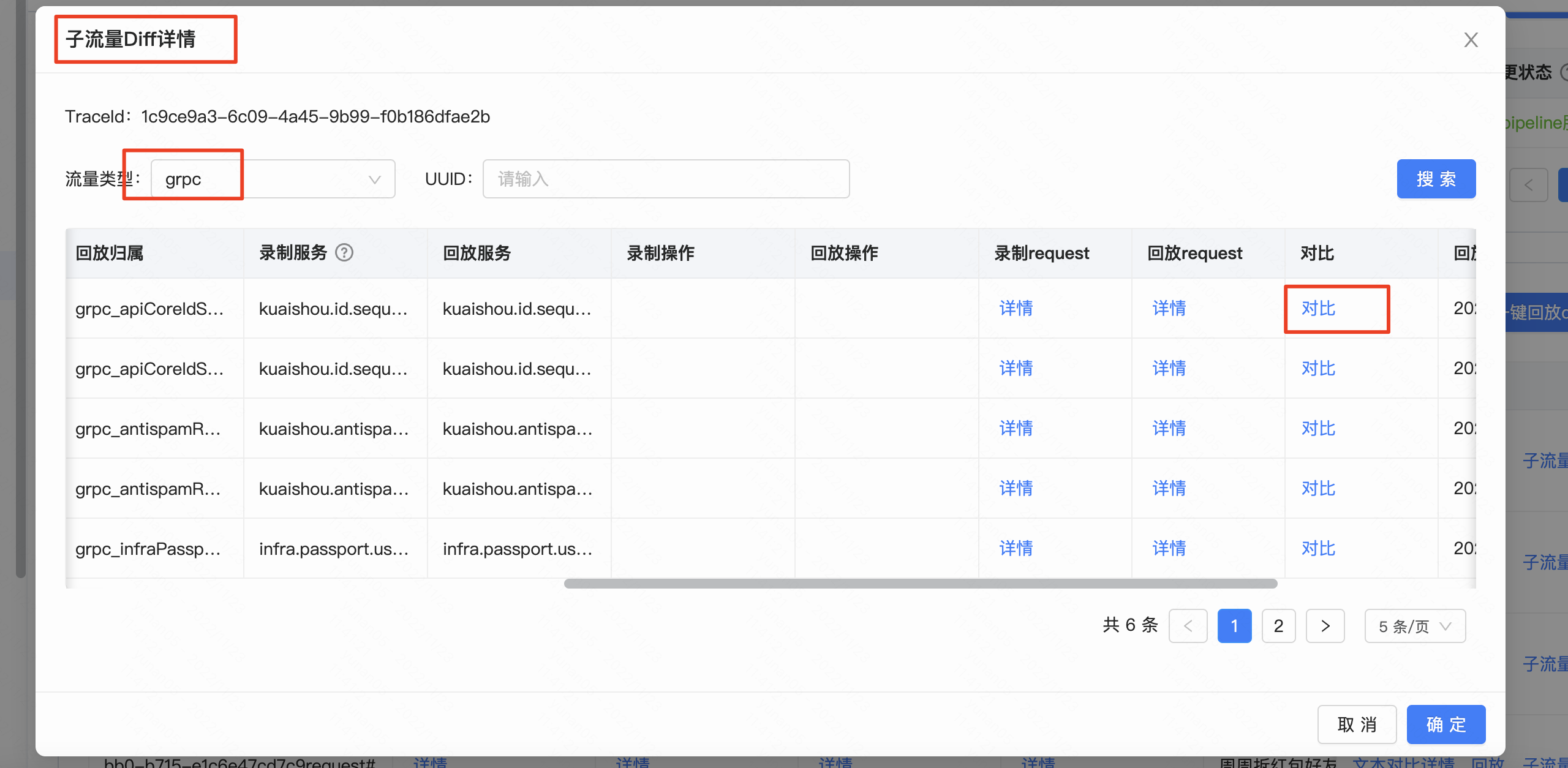
3.3.3 单条流量文本diff
只是单纯对比两条流量的response, 如下图。

3.3.4 流量管理
流量录制回放是一个存储高消耗的使用场景,面临较高的存储成本, 因此对于不活跃的录制回放任务,我们只存储三个月,三个月后我们会定期删除。